深度學習Paper系列(04):Variational Autoencoder (VAE)
上一回我們介紹了GAN生成對抗網絡,而我們今天要來講另一種生成圖片的模型VAE。
論文回顧
VAE實際上是基於所謂的Autoencoder的架構,其論文稱叫做:

對於Max Welling這位大神,其除了VAE外,其在Graph Neural Network上也有很重要的貢獻。
簡單介紹
我們知道VAE是基於所謂的Autoencoder架構,那Autoencoder是什麼呢,Autoencoder中文翻譯成自動編碼器,道理很簡單,其就是包含一個Encoder和Decoder。
我們知道圖片是一個維度非常大的矩陣,所以我們可以透過Encoder把輸入的圖片壓縮成一個維度非常小的representation,在VAE上有一個專有名詞叫做Bottleneck!而這個representation可以藉由Decoder還原回原來的圖片。
所以在訓練Autoencoder的時候我們會設定說,我們想要把我們的照片壓縮到什麼樣的維度,學習目標就是希望原始和重建後的影像一模一樣。
那VAE是什麼呢,我本人自己覺得其實VAE和Autoencoder雖然名字和架構很像,但是理論基礎非常不一樣,
Autoencoder是學好一個representation來表達原始資料
VAE則是學好一個「分布」來表達原始資料分布
概念上來說Autoencoder和VAE都是希望把原始照片壓縮到低維度空間。但是VAE訓練上目標是能更學到一個分布,所以一旦這個分布被我們學好了,我們就可以從這個分布隨便挑一個點,然後丟進去Decoder就可以產生一張假照片。
所以這邊VAE和GAN是非常不一樣的,GAN繞過了學低維度分布,直接學真實照片的分布,而VAE就是扎扎實實地去學真實資料的低維度分布。
這邊大家可能就想問阿幹嘛多此一舉去學真實資料的低維度分布,直接學真實資料分布不就好。其實是這樣,我們今天想要用從VAE生成照片就是從學好的低維度分布取樣一個點,這個點通常是一組向量,然後我們再用Decoder把這個向量轉換成假照片。所以說這邊假如說我們想要生成特定頭髮顏色、特定膚色、特定五官的人臉照片時,我們其實可以很輕易的去更改這些向量的值去做調整。但是GAN他就是硬生生地把一堆雜訊轉成假照片,要去調整雜訊去生成特定圖片非常非常困難。此外也因為VAE具備這個良好的特性,也可以進一步的和文字、語音做結合。

理論
不過呢!因為我們的VAE是真的去學分布這件事,所以他的數學推導過程非常噁心。我會盡量寫的淺顯易懂!
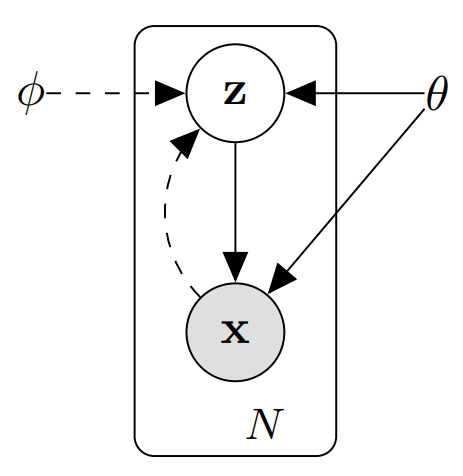
假設我們有一組資料集X = {x_1, x_2, x_3, …., x_N},總共N個照片。我們設照片存在的空間為x,而被encoder壓縮後的空間為z。
在生成模型當中,我們的目標是能夠學出真實資料的分布p(x)

其中這邊
p(x|z)為Likelihood條件機率分布,也就是在給定一個點z_i,我們把他轉成照片x_i的機率
p(z)是我們的先驗機率分布prior distribution,從這裡面sample的點為z_i
而通常p(z)我們設為高斯分布,然後我們透過p(x|z)積分z去近似真實照片的分布。但是有點sense的朋友看到這邊應該就會有點疑問,如果我們真的要用這樣的方式去找p(x),那不就是要窮盡各種z嗎?
沒錯!這個地方作者有提到,如果我們要用這種方式的話,在計算上的確是不可行的,所以我們會透過設計另一個方程式q(z|x)去近似我們的posterior

如此一來我們可以透過q(z|x)縮小z的範圍。而在這邊,p(x|z)就是我們VAE中的decoder、q(z|x)就是VAE中的enocder。
OK下一步我們就是要來求解我們的方程式。那我們現在的目標已經越來越明確了,我們想要學習一個分布q(z|x)來近似我們的posterior p(z|x)。所以這邊我們可以把這個問題寫成
展開這個式子我們可以得到
因為p(x)不和z相關,所以
最後我們就可以根據上面的推導,定義evidence lower bound (ELBO),也就是我們VAE的loss function
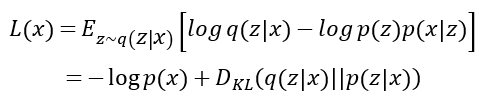
我們可以看到,如果我們今天想要最小化這個loss,
第一項來說,對應到的就是decoder。我們想要最大化p(x),也就是我們想要盡量讓我們從p(x)取樣出來的資料有越高的機率越接近真實照片。
第二項來說,對應到的就是encoder。就是我們希望我們最小化q(z|x)和p(z|x)之間的差異程度。
OK現在我們有了loss function我們要來看看這些方程式能不能做微分以用來做梯度下降更新encoder和decoder的權重。為了方便大家更容易理解參數更新,我們以θ表示為decoder的參數、φ表示為encoder的參數
首先我們先來看看decoder的部分,如果對decoder微分其梯度為

我們可以看decoder相關的參數都位於分子,所以計算梯度上沒有什麼太大問題。
而在encoder中,因為我們可以看到期望值裡面有φ
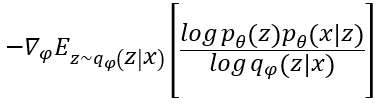
所以微分上不是那麼容易。所以這邊我們會利用一個小技巧來簡化這個問題,這邊我們會假設q(z|x)為高斯分布。然後我們就可以把z改寫成
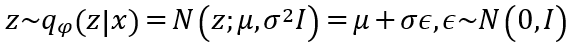
如此一來我們就可以把上面微分的式子改寫成
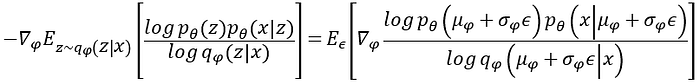
如此一來我們就可以來計算encoder相對應的梯度了!
所以我們來總結一下上述講到的東西
Encoder
我們在這邊等於說是直接把照片壓縮後的分布假設為高斯分布,這樣的好處是我們可以簡化Encoder的在做梯度下降的時候難以微分的問題,所以等於說我們到頭來,都是在透過神經網絡在學這個高斯分布的平均值和標準差
Decoder
在這邊其做的事情就是從學出來的分布來生成圖片,所以我們希望透過已經學好的平均值和標準差,再從高斯分布N(0,I) sample ϵ,就可以得到一組z,其經過decoder後就可以輸出一張假的照片
結語
不過相信大家看到這邊應該會有些疑問,這樣把分布直接假設成高斯分布去學平均值和標準差的方法是不是有點太過簡單了?
事實上沒錯,其實VAE產生出來的圖片相較於GAN來說模糊很多,但是也因為VAE認真去學這個標準差和平均值,所以我們可以透過調控ϵ,生成特定的圖片。
如VAE原始論文給出的圖片

我們可以看到其實不管是數字和人臉的部分,其感覺就是很像把資料集有的照片做個平均的感覺,但事實上VAE做的事情就真的是假設其為高斯分布,然後只去學平均值和標準差,所以產生出來的圖片看起來大概只有尚可而已。
但是因為VAE本身的特性和架構比GAN來得好很多,所以也不少後來研究VAE的學者想盡辦法去改進模型生成更真實的影像
Reference:
[1] Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
