66個視覺語言模型VLM經典論文
93 min readDec 21, 2023
隨著各個大型語言模型(Large Language Models, LLM)的進展,也開始帶動了視覺語言模型(Vision Language Models, VLM)的發展,最經典的模型像是GPT-4V和Gemini,以及開源社群LLaVA等,所以今天要來帶大家看我自己看過的各個經典視覺語言模型論文,另外這邊一樣我會按照時間順序列出來,不過這篇不包含影音模態,也不包含影像和影片生成的模型,關於這些之後我會出另外一篇講經典的擴散模型論文、有機會的話也希望可以出一個講multimodality的,能夠吃image、text、video、audio,甚至是action。OK那我們就趕快開始吧!
1. VSE
- 論文名稱:Deep Visual-Semantic Alignments for Generating Image Descriptions
- 發布時間:2014/12/07
- 發布單位:史丹佛大學
- 簡單摘要:RCNN吃圖片、BRNN吃文字,早期多模態模型之一
- 閱讀重點:Representing images、Representing sentences、Alignment objective、Decoding text segment alignments to images、generating descriptions
- 中文摘要:我們提出了一個模型,用於生成圖像及其區域的自然語言描述。我們的方法利用圖像及其句子描述的數據集,來學習語言和視覺數據之間的跨模態對應關係。我們的對齊模型結合了卷積神經網絡(CNN)處理圖像區域、雙向循環神經網絡(RNN)處理句子,並通過多模態嵌入實現了兩種模態的對齊。接著我們描述了一種多模態循環神經網絡架構,利用推斷的對齊訊息學習生成圖像區域的新描述。我們展示了我們的對齊模型在 Flickr8K、Flickr30K 和 MSCOCO 數據集的檢索實驗中取得了最先進的結果。然後我們展示了生成的描述在全圖像和新的區域級標註數據集上明顯優於基於檢索的標準模型。
- 論文連結:https://arxiv.org/pdf/1412.2306.pdf

2. VSE++
- 論文名稱:VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
- 發布時間:2017/07/18
- 發布單位:多倫多大學、Google
- 簡單摘要:把難分的負樣本加入loss,讓VSE準確率更高
- 閱讀重點:hard negative mining、recall R@K、Sum of Hinges(SH) loss、Max of Hinges (MH) loss、取樣hard negative實際上怎麼做
- 中文摘要:我們提出了一種新的技術,用於跨模態檢索的視覺語義嵌入學習。受到硬負採樣、結構化預測中的硬負例和排名損失函數的啟發,我們對用於多模態嵌入的常見損失函數進行了簡單的修改。這種修改結合了微調和增強數據的使用,在檢索效果方面取得了顯著的進展。我們在 MS-COCO 和 Flickr30K 數據集上展示了我們的方法 VSE++,通過消融研究和與現有方法的比較。在 MS-COCO 數據集上,我們的方法在標題檢索方面比最先進的方法提升了8.8%,在圖像檢索方面提升了11.3%(在 R@1 指標上)。
- 論文連結:https://arxiv.org/pdf/1707.05612.pdf

3. SCAN
- 論文名稱:Stacked Cross Attention for Image-Text Matching
- 發布時間:2018/05/21
- 發布單位:Microsoft、JD AI Research
- 簡單摘要:對image-text和text-image都做attention得到更好的表徵
- 閱讀重點:Image-Text Stacked Cross Attention、Text-Image Stacked Cross Attention、Alignment的loss function、Bottom-Up Attention
- 中文摘要:這篇論文探討了圖像與文字之間的匹配問題。推斷物體或其他突出事物(例如雪、天空、草坪)與句子中相應單詞之間的潛在語義對齊,可以捕捉視覺和語言之間微妙的交互作用,使圖像與文字的匹配更具可解釋性。先前的研究要麼僅僅是將所有可能的區域和單詞配對的相似性聚合起來,而沒有區分重要和不重要的單詞或區域,要麼使用多步驟的注意力過程來捕捉有限數量的語義對齊,使其解釋性較差。所以在這篇論文中,我們提出了堆疊交叉注意力機制,利用圖像區域和句子中的單詞作為上下文來發現完整的潛在對齊,推斷圖像與文字之間的相似性。我們的方法在 MS-COCO 和 Flickr30K 數據集上取得了最先進的結果。在 Flickr30K 上,我們的方法相對於目前最佳方法,在圖像查詢的文本檢索方面提升了22.1%,在文字查詢的圖像檢索方面提升了18.2%(基於 Recall@1)。在 MS-COCO 上,我們的方法相對提高了17.8%的句子檢索和16.6%的圖像檢索(基於使用 5K 測試集的 Recall@1)。
- 論文連結:https://arxiv.org/pdf/1803.08024.pdf

4. ViLBERT
- 論文名稱:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- 發布時間:2019/08/06
- 發布單位:喬治亞理工學院、Facebook(Meta)、俄勒岡州立大學
- 簡單摘要:把文字和圖片特徵交叉丟到co-attentional的BERT
- 閱讀重點:co-attention transformer layer、Extending BERT to Jointly Represent Images and Text、Training Tasks and Objectives
- 中文摘要:我們提出了ViLBERT(Vision-and-Language BERT),這是一個用於學習影像內容和自然語言的任務無關聯合表徵模型。我們將BERT架構擴展為多模態雙流模型,通過兩個分開的流程分別處理視覺和文字輸入,透過共注意力變換層相互交互。我們通過兩個代理任務在大型自動收集的Conceptual Captions數據集上預訓練模型,然後通過對基礎架構進行小幅度修改的方式,將其轉移到多個已建立的視覺和語言任務上 ,其中包括視覺問答、視覺常識推理、指稱表達和基於語句的圖像檢索。與現有的任務特定模型相比,我們觀察到在各任務上都取得了顯著的改進 ,在所有四個任務上達到了最先進水準。我們的工作代表著從僅在任務訓練中學習視覺和語言之間的基礎關係轉向將視覺基礎建立為可預訓練和可轉移的能力。
- 論文連結:https://arxiv.org/pdf/1908.02265.pdf
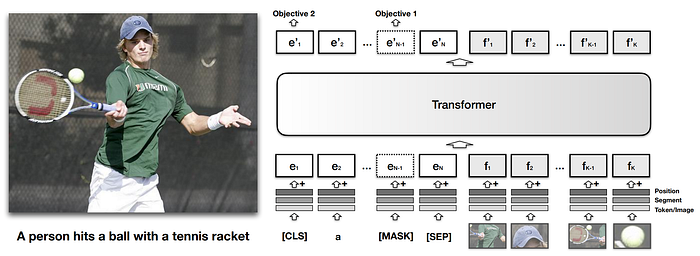
5. VisualBERT
- 論文名稱:VisualBERT: A Simple and Performant Baseline for Vision and Language
- 發布時間:2019/08/09
- 發布單位:加州大學洛杉磯分校、Allen Institute、北京大學
- 簡單摘要:利用兩個視覺基礎任務來預訓練BERT
- 閱讀重點:architecture、joint contextualized representations、Task-Agnostic Pre-Training、Task-Specific Pre-Training
- 中文摘要:我們提出了VisualBERT,這是一個用於建模各種視覺和語言任務的靈活框架。VisualBERT由一串Transformer層組成,通過自注意力隱式對齊輸入文本和相關輸入圖像中的區域元素。另外我們進一步提出了兩種基於視覺的語言模型目標,用於在圖像標題數據上預訓練VisualBERT。對包括VQA、VCR、NLVR2和Flickr30K在內的四個視覺和語言任務的實驗表明,VisualBERT在簡化的情況下超越了或與最先進的模型相媲美。進一步的分析顯示,VisualBERT可以在沒有明確監督的情況下將語言元素與圖像區域對應起來,甚至對語法關係敏感,例如追蹤動詞與對應其參數的圖像區域之間的聯繫。
- 論文連結:https://arxiv.org/pdf/1908.03557.pdf
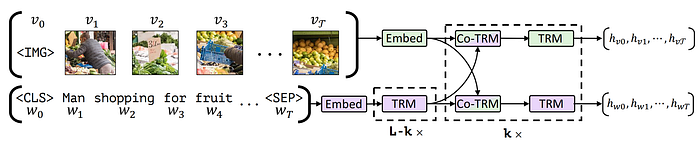
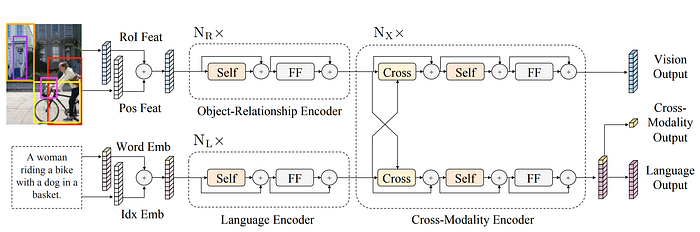
6. LXMERT
- 論文名稱:LXMERT: Learning Cross-Modality Encoder Representations from Transformers
- 發布時間:2019/08/20
- 發布單位:北卡羅來納大學教堂山分校
- 簡單摘要:我們用了3個encoder,1個對文字、1個對圖像、1個跨模態
- 閱讀重點:Sentence Embeddings、Image Embeddings、Single-Modality Encoders、Cross-Modality Encoder、5個Pre-Training Tasks
- 中文摘要:我們提出了LXMERT(從Transformer學習跨模態編碼器表示),以學習視覺和語言之間的聯繫。LXMERT由三個編碼器組成:物體關係編碼器、語言編碼器和跨模態編碼器。通過大量的圖像-句子對來進行預訓練,而在這之中我們使用五個不同的任務:遮蔽語言建模、遮蔽物體預測(特徵回歸和標籤分類)、跨模態匹配和圖像問答,我們賦予了模型連接視覺和語言語義的能力。在對預訓練參數進行微調後,我們的模型在兩個視覺問答數據集(VQA和GQA)上實現了最先進的結果。我們還展示了預訓練跨模態模型的普適性,將其適應到挑戰性的視覺推理任務NLVR2上,將先前最佳結果提高了22%絕對值(從54%到76%)。最後,我們進行了詳細的消融研究,證明了我們新穎模型組件和預訓練策略對我們強大結果的重要貢獻;同時展示了不同編碼器的多種注意力可視化。
- 論文連結:https://arxiv.org/pdf/1908.07490.pdf
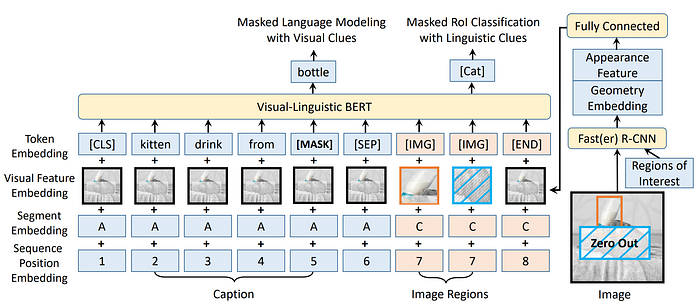
7. VL-BERT
- 論文名稱:VL-BERT: Pre-training of Generic Visual-Linguistic Representations
- 發布時間:2019/08/22
- 發布單位:中國科學技術大學、Microsoft
- 簡單摘要:把文字和圖像區域的embedding丟進去BERT預訓練
- 閱讀重點:Model Architecture、Token Embedding、Visual Feature Embedding、Segment Embedding、Sequence Position Embedding
- 中文摘要:我們提出了一個名為VL-BERT的新型視覺-語言任務的通用表徵。VL-BERT使用了簡單而強大的Transformer模型作為基礎架構,並擴展了其功能,可以接受視覺和語言嵌入特徵作為輸入。其設計適用於大多數視覺-語言的後續任務。為了更好地利用這種通用表徵,我們在大規模的Conceptual Captions數據集以及純文本語料庫上對VL-BERT進行了預訓練。大量的實驗分析表明,預訓練過程可以更好地對齊視覺-語言的線索,並使後續任務受益,如視覺常識推理、視覺問答和指稱表達理解。值得注意的是,VL-BERT在VCR基準測試的單模型排行榜中取得了第一名。
- 論文連結:https://arxiv.org/pdf/1908.08530.pdf
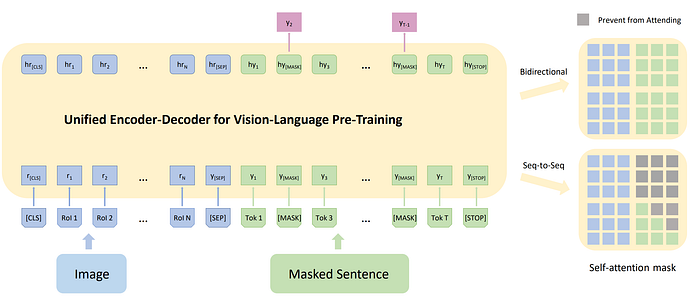
8. Unified VLP
- 論文名稱:Unified Vision-Language Pre-Training for Image Captioning and VQA
- 發布時間:2019/09/24
- 發布單位:Microsoft、密西根大學
- 簡單摘要:統一視覺語言理解和生成,用bidirectional和seq2se2預訓練
- 閱讀重點:unified encoder-decoder、bidirectional objective、sequence to sequence objective、Self-attention mask
- 中文摘要:大規模的跨模態表徵學習方法在影像和文字配對上,為用於視覺與語言任務的主流方式。現有方法通常將影像區域特徵和文本特徵簡單串接,作為預訓練模型的輸入,利用自我注意力以暴力方式學習影像與文字之間的語義對齊。而本文提出了一種名為Oscar(Object-Semantics Aligned Pre-training)的新學習方法,利用影像中檢測到的物件標籤作為錨點,顯著簡化對齊的學習。我們的方法基於一個觀察:影像中突出的物件可以準確地被檢測到,並且通常在配對的文字中提到。最後我們在650萬組公共文本-影像對上預訓練了一個Oscar模型,並在下游任務上進行了微調,在六個知名的視覺與語言理解與生成任務上創造了新的最先進成果。
- 論文連結:https://arxiv.org/pdf/1909.11059.pdf
9. UNITER
- 論文名稱:UNITER: UNiversal Image-TExt Representation Learning
- 發布時間:2019/09/25
- 發布單位:Microsoft
- 簡單摘要:加入圖像文字匹配和字區域對齊任務訓練一個通用encoder
- 閱讀重點:Masked Language Modeling、Masked Region Modeling、mageText Matching、Word-Region Alignment、Optimal Transport
- 中文摘要:我們介紹了一種稱為UNITER的通用影像文字表徵方法,通過在四個影像文字數據集(COCO、Visual Genome、Conceptual Captions和SBU Captions)上進行大規模預訓練學習而得到。這種表示方法可以應用在多種不同的視覺與語言任務中,並產生聯合的多模態嵌入。我們設計了四種預訓練任務:遮罩語言模型(MLM)、遮罩區域模型(MRM,有三種變體)、圖像-文本匹配(ITM)和詞-區域對齊(WRA)。與以往對兩種模態進行聯合隨機遮罩的方法不同,我們使用了條件遮罩在預訓練任務中(即遮罩語言/區域建模是基於對圖像/文本的完整觀察)。除了ITM用於全局影像-文字對齊外,我們還提出了利用最佳化運輸(OT)的WRA,明確地在預訓練過程中鼓勵詞語和影像區域之間的細粒度對齊。全面的分析表明,條件遮罩和基於OT的WRA都有助於更好的預訓練。我們還進行了全面的消融研究,以找到最佳的預訓練任務組合。大量實驗表明,UNITER在六個V+L任務(九個數據集)中取得了新的最先進成果,包括視覺問答、圖像-文本檢索、指稱表達理解、視覺常識推理、視覺推理和NLVR2。
- 論文連結:https://arxiv.org/pdf/1909.11740.pdf

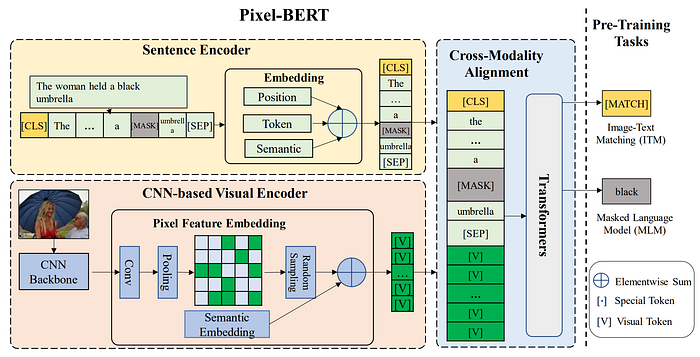
10. Pixel-BERT
- 論文名稱:Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
- 發布時間:2020/04/02
- 發布單位:北京科技大學、中山大學、Microsoft
- 簡單摘要:圖像特徵,從region-based換成pixel-based
- 閱讀重點:Revisit Transformer、Sentence Feature Embedding、Image Feature Embedding、Cross-Modality Module、Pixel Random Sampling
- 中文摘要:我們提出了 Pixel-BERT,透過深度多模態 Transformer,將圖像像素與文字進行對齊,共同學習視覺和語言嵌入在一個統一的框架中。我們的目標是直接從圖像和句子配對中建立更準確、更全面的圖像像素與語言語義之間的關聯,而不是像最近的視覺和語言任務那樣使用基於區域的圖像特徵。Pixel-BERT 在像素和文字級別上對齊語義連接,解決了視覺和語言任務的特定視覺表徵的限制。它還減輕了邊界框註釋的成本,克服了視覺任務和語言語義之間標籤不平衡的問題。為了為下游任務提供更好的表示,我們使用 Visual Genome 數據集和 MS-COCO 數據集的圖像和句子配對進行了通用的端到端模型預訓練。另外我們提出使用隨機像素抽樣機制來增強視覺表示的穩定性,並應用遮罩語言模型和圖像-文字匹配作為預訓練任務。通過對我們預訓練模型在下游任務上進行廣泛的實驗,顯示我們的方法在包括視覺問答(VQA)、圖像-文字檢索和真實自然語言視覺推理(NLVR)等下游任務中取得了最先進的效果。特別是,在公平比較下,我們在 VQA 任務中單一模型的表現比SOTA提高了2.17個點。
- 論文連結:https://arxiv.org/pdf/2004.00849.pdf
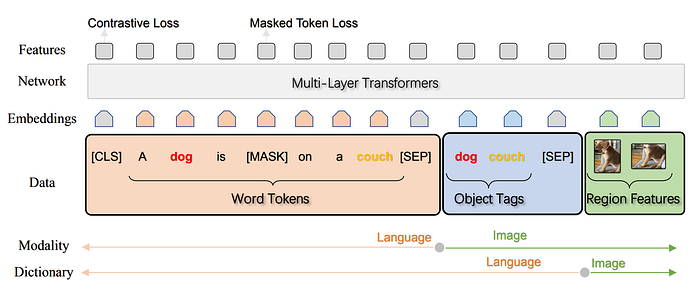
11. Oscar
- 論文名稱:Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
- 發布時間:2020/04/13
- 發布單位:Microsoft、華盛頓大學
- 簡單摘要:除了文字、區域影像,物件標籤也一起丟進去模型預訓練
- 閱讀重點:VLP Ambiguity和grounding問題、Word-Tag-Image triple、Masked Token Loss、Contrastive Loss
- 中文摘要:大規模的跨模態表徵學習方法在影像和文字配對方面,用於視覺與語言任務變得越來越流行。現有方法通常將影像區域特徵和文本特徵簡單串接,作為預訓練模型的輸入,利用自我注意力以暴力方式學習影像與文字之間的語義對齊。所以本文提出了一種名為Oscar(Object-Semantics Aligned Pre-training)的新學習方法,利用影像中檢測到的物件標籤作為錨點,顯著簡化對齊的學習。另外我們的方法基於一個觀察:影像中突出的物件可以準確地被檢測到,並且通常在配對的文字中提到。最後我們在650萬組公共文本-影像對上預訓練了一個Oscar模型,並在下游任務上進行了微調,在六個知名的視覺與語言理解與生成任務上創造了新的最先進成果。
- 論文連結:https://arxiv.org/pdf/2004.06165.pdf
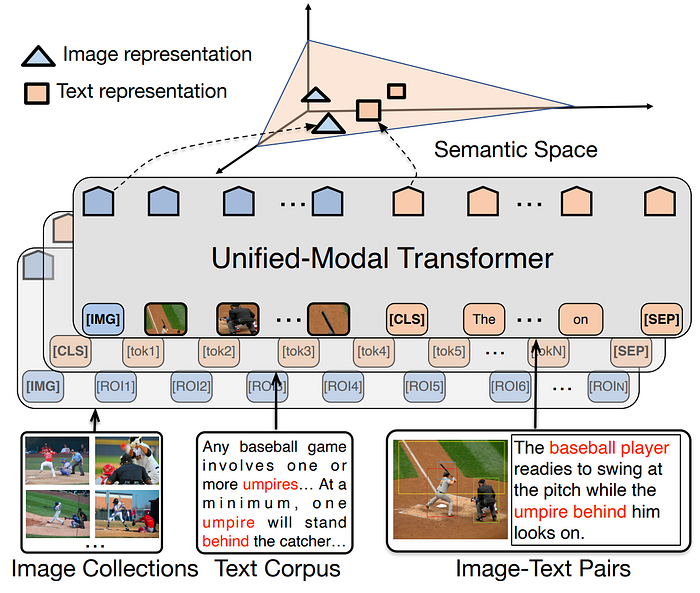
12. UNIMO
- 論文名稱:UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
- 發布時間:2020/12/31
- 發布單位:百度
- 簡單摘要:除了視覺和語言外,結合了跨模態的對比學習
- 閱讀重點:Cross-Modal Contrastive Learning、Visual Learning、Language Learning、Text Rewriting、Image/Text Retrieval
- 中文摘要:這項研究提出了統一模態預訓練架構UNIMO,它能有效地適應單模態和多模態理解與生成任務。傳統的預訓練方法通常僅能利用單模態數據(如文字或圖像)或有限的多模態數據(如圖像-文字配對)。而UNIMO能充分利用大規模的自由文本語料庫和圖像集,提升視覺和文字理解能力,並透過跨模態對比學習(CMCL)將文字和視覺資訊對齊到一個統一的語義空間。我們的模型能運用非配對的單模態數據,學習更通用的表徵,並在統一的語義空間中相互增強。在我們的實驗結果顯示,UNIMO在多項單模態和多模態任務中顯著提升了性能。
- 論文連結:https://arxiv.org/pdf/2012.15409.pdf
13. VinVL
- 論文名稱:VinVL: Revisiting Visual Representations in Vision-Language Models
- 發布時間:2021/01/02
- 發布單位:Microsoft、華盛頓大學
- 簡單摘要:用更大的模型、更多的資料、更好的方法得到更好的視覺表徵
- 閱讀重點:Object Detection Pre-training、Model Architecture Selection、Efficient region feature extractor、OSCAR+
- 中文摘要:這篇論文詳細探討了如何改進視覺語言任務的視覺表徵,並發展了一個改進的物體檢測模型,以提供圖像的物體中心表徵。新模型相比於最廣泛使用的「bottom-up and top-down」模型更大、更適用於視覺語言任務,並在更大的訓練語料庫上進行預訓練,結合了多個公開的標註物體檢測數據集。因此它可以生成更豐富的視覺物體和概念表徵。而在先前的視覺語言研究中,主要著眼於改進視覺-語言融合模型,而對物體檢測模型的改進則鮮少有涉及,所以我們在本篇論文中,證明視覺特徵在視覺語言模型中非常重要。而在實驗中,我們將新的物體檢測模型生成的視覺特徵輸入基於Transformer的視覺語言融合模型(Oscar),並利用改進的方法對視覺語言模型進行預訓練,然後在多種下游視覺語言任務上進行微調。我們的結果顯示,新的視覺特徵顯著改善了所有視覺語言任務的性能,在七個公開基準測試中創造了新的最先進結果。
- 論文連結:https://arxiv.org/pdf/2101.00529.pdf

14. VL T5
- 論文名稱:Unifying Vision-and-Language Tasks via Text Generation
- 發布時間:2021/02/04
- 發布單位:北卡羅來納大學教堂山分校
- 簡單摘要:把所有預訓練任務統一,直接讓模型預測text labels
- 閱讀重點:Visual Embeddings、Text Embeddings、Architecture、Task-Specific和Unified Framework的比較
- 中文摘要:這篇論文提出了一個統一的框架,用於視覺與語言學習,不需為每個任務設計特定的架構和目標。我們的方法採用相同的語言建模目標,即多模態條件文本生成,在單一架構中學習不同的任務,根據視覺和文本輸入生成文本標籤。而在七個流行的視覺與語言測試中,包括視覺問答、表達理解、視覺常識推理等,大多數以前被建模為判別任務的測試,我們的生成方法(使用單一統一架構)達到了與最近特定任務最先進視覺與語言模型相媲美的性能。此外我們的生成方法在罕見答案的問題上表現出更好的泛化能力。同時我們展示了我們的框架允許在單一架構中進行多任務學習,使用單一參數集達到了與分開優化的單一任務模型相似的性能。
- 論文連結:https://arxiv.org/pdf/2102.02779.pdf
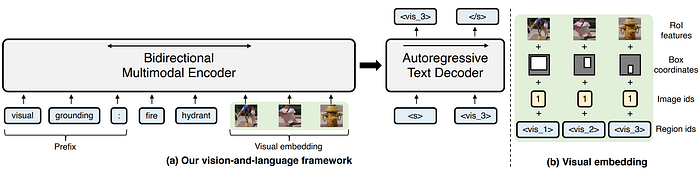
15. ViLT
- 論文名稱:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 發布時間:2021/02/05
- 發布單位:Naver AI Lab
- 簡單摘要:簡化embedding,結合BERT訓練方式和ViT模型
- 閱讀重點:Patch Projection、Image Text Matching、Masked Language Modeling、Whole Word Masking、Image Augmentation
- 中文摘要:這份論文探討了視覺與語言預訓練(VLP)對各種聯合視覺與語言下游任務的性能提升。目前的VLP方法主要依賴於圖像特徵提取過程,其中大部分涉及區域監督(例如物體檢測)和卷積架構(例如ResNet)。然而在文獻中被忽略的是,這樣的方法存在問題,像是在效率/速度方面,如果提取輸入特徵就需要比多模態交互步驟更多的計算量;另外表達能力上,則受限於視覺嵌入器和其預定義視覺詞彙的表達能力。因此本文提出了一個簡化的VLP模型,Vision-and-Language Transformer(ViLT),這個模型在處理視覺輸入時僅使用與處理文本輸入相同的無卷積方法。在研究顯示中,相較於先前的VLP模型,ViLT速度提升了數十倍,同時在下游任務的性能表現上也具有競爭力甚至更好。
- 論文連結:https://arxiv.org/pdf/2102.03334.pdf
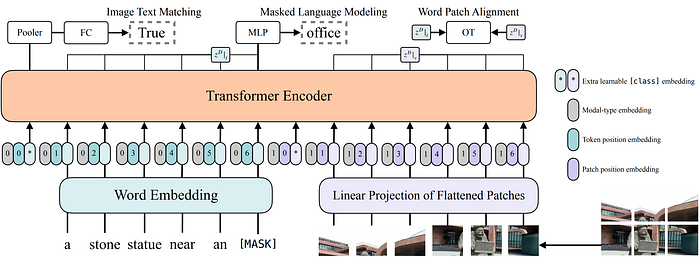
16. SimVLM
- 論文名稱:SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
- 發布時間:2021/02/05
- 發布單位:Google、華盛頓大學
- 簡單摘要:不用複雜的訓練任務,只用簡單的ViT模型和PrefixLM方法
- 閱讀重點:Prefix Language Modeling、Architecture、zero-shot generalization
- 中文摘要:最新的視覺和文字表示聯合建模在視覺-語言預訓練(VLP)方面取得了驚人的成果。但是現有方法需要昂貴的標註,包括乾淨的圖像標題和區域標籤,限制了現有方法的可擴展性,並且由於引入了多個特定於數據集的目標,使得預訓練程序變得複雜。所以在這項工作中,我們放寬了這些限制,提出了一個簡約的預訓練框架,名為Simple Visual Language Model(SimVLM)。與以往的方法不同,SimVLM通過利用大規模弱監督來減少訓練的複雜性,並且使用單一的前綴語言建模目標進行端到端訓練。在不使用額外數據或特定任務定制的情況下,該模型顯著優於先前的預訓練方法,在廣泛的判別性和生成性視覺-語言基準測試中取得了新的最先進結果,包括VQA(+3.74% vqa-score)、NLVR2(+1.17% 精度)、SNLI-VE(+1.37% 精度)和圖像標註任務(+10.1% 平均CIDEr分數)。此外,我們展示了SimVLM具有強大的泛化和轉移能力,能夠實現零樣本行為,包括開放式視覺問答和跨模態轉移。
- 論文連結:https://arxiv.org/pdf/2108.10904.pdf
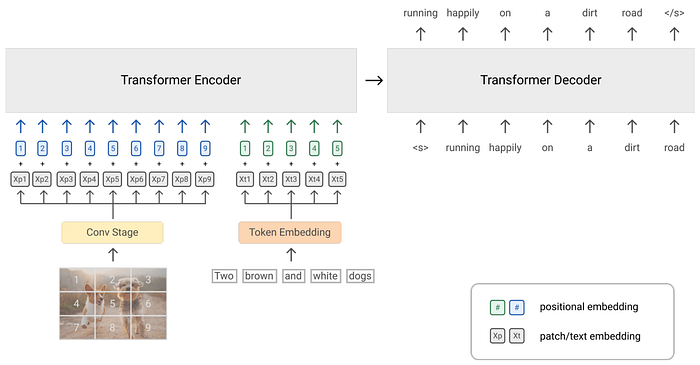
17. ALIGN
- 論文名稱:Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- 發布時間:2021/02/11
- 發布單位:Google
- 簡單摘要:即使資料雜訊多,但規模大也能訓練出好模型
- 閱讀重點:Image-based filtering、Text-based filtering、Noisy Image-Text Pairs、Image-Text Matching & Retrieval、Visual Classification
- 中文摘要:預訓練表徵對於許多自然語言處理和感知任務變得至關重要。雖然自然語言處理中的表徵學習已轉向在沒有人類標註的原始文本上進行訓練,但視覺和視覺語言表徵仍然嚴重依賴昂貴或需要專業知識的精心訓練數據集。對於視覺應用,表徵大多是使用帶有明確類別標籤的數據集學習,如 ImageNet 或 OpenImages。但是對於視覺語言,流行的數據集如 Conceptual Captions、MSCOCO 或 CLIP 都涉及到非常複雜的數據收集(和清理)過程。這種昂貴的精心編輯過程限制了數據集的規模,因此阻礙了訓練模型的擴展。所以在這篇論文中,我們利用了 Conceptual Captions 數據集中超過十億個圖像替代文字對,無需昂貴的過濾或後處理步驟。通過一種簡單的雙編碼器架構,學會了使用對比損失對圖像和文字對進行視覺和語言表示的對齊。我們也展示了我們語料庫的規模可以彌補其本身的雜訊,讓我們即使是使用這樣簡單的學習方案,也能產生最先進的表徵,讓我們的視覺表徵在遷移到 ImageNet 和 VTAB 等分類任務時表現強勁。最後對齊的視覺和語言表徵實現了零標註圖像分類,並在 Flickr30K 和 MSCOCO 圖像文字檢索基準上取得了新的最先進結果,即使與更複雜的交叉注意力模型相比,效果也很非常的好。這些表徵還能夠進行複雜的文本和文本+圖像查詢的跨模態搜索。
- 論文連結:https://arxiv.org/pdf/2102.05918.pdf
18. CLIP
- 論文名稱:Learning Transferable Visual Models From Natural Language Supervision
- 發布時間:2021/02/26
- 發布單位:OpenAI
- 簡單摘要:用大量的數據簡單粗暴的將圖像和文字通通映射到同一個空間
- 閱讀重點:創建Large Dataset、Pre-Training Method、Scaling Model、Zero-Shot Transfer、Representation Learning、Distribution Shift
- 中文摘要:這篇論文討論了一個新的方法,用文字直接教導電腦視覺系統。傳統的系統需要預先訓練,並且僅能辨識特定物件。但這種方式的監督相對受限,因為需要更多標註過的資料來指定其他視覺概念。相反地,這個新方法利用原始文字訓練,讓電腦自己學習圖像,使用這個方式在網路收集的 4 億張圖片和文字配對的資料集上,成功地建立了最先進的圖像表徵。在進行預先訓練後,自然語言能夠參考已學習的視覺概念,甚至描述新的概念,並將模型零樣本地轉移到其他任務上。經過對超過 30 個不同電腦視覺資料集的評估,包括文字辨識、影片動作辨識、地理定位和細粒度物件分類等,結果顯示這個模型在大多數任務上表現良好,有時效果甚至與完全監督訓練的基準模型可以抗衡,例如在 ImageNet 上,不需使用其訓練的 128 萬張圖片,就能與原始 ResNet-50 辨識準確度相匹配。
- 論文連結:https://arxiv.org/pdf/2103.00020.pdf

19. ViLD
- 論文名稱:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
- 發布時間:2021/04/28
- 發布單位:Google、Nvidia
- 簡單摘要:知識蒸餾配CLIP架構讓zero-shot detection超越supervised
- 閱讀重點:Image and Text embedding、Replacing classifier with text embeddings、Distilling image embeddings、model ensembling
- 中文摘要:我們目標在推進開放詞彙的物件檢測,即能根據任意文字描述進行物件檢測。其中的主要挑戰是訓練數據的可用性。進一步擴展現有物件檢測數據集中的類別數量成本高昂。所以為了克服這一挑戰,我們提出了ViLD,一種通過視覺和語言知識蒸餾的訓練方法。我們的方法將預先訓練的開放詞彙圖像分類模型(教師)的知識,提煉到兩階段檢測器(學生)中。具體來說,我們使用教師模型對類別文字和物件提議的圖像區域進行編碼,接著我們訓練一個學生檢測器,其檢測框的區域嵌入與教師推斷的文字和圖像嵌入相匹配。最後我們在LVIS上進行評估,將所有罕見類別作為未在訓練中見過的新類別,ViLD使用ResNet-50骨幹獲得了16.1的mask APr,甚至比監督式對應模型提高了3.8。當使用更強的教師模型ALIGN進行訓練時,ViLD達到了26.3的APr。該模型可以直接轉移到其他數據集而無需微調,在PASCAL VOC上達到了72.2的AP50,在COCO上達到了36.6的AP,在Objects365上達到了11.8的AP。在COCO上,ViLD在新的AP上超越先前的最新技術水平4.8,在整體AP上超過11.4。
- 論文連結:https://arxiv.org/pdf/2104.13921.pdf
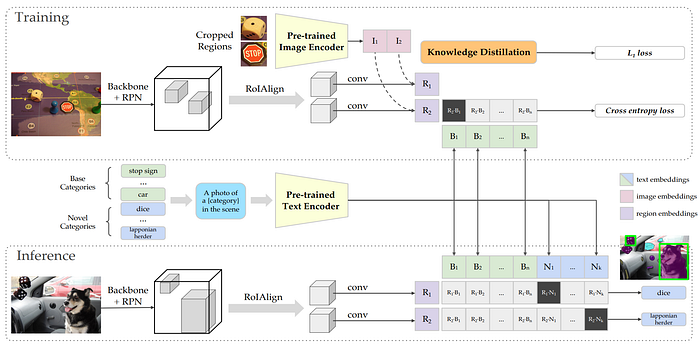
20. Frozen
- 論文名稱:Multimodal Few-Shot Learning with Frozen Language Models
- 發布時間:2021/06/25
- 發布單位:DeepMind
- 簡單摘要:凍結語言模型,直接讓visual embedding適應LM
- 閱讀重點:Frozen Language Models、Vision Encoder和Prefix、Training和Inference、Few-Shot Learner
- 中文摘要:當規模足夠大時,自回歸語言模型展現了學習新語言任務的明顯能力,只需提示少量範例即可。所以我們提出了一個簡單而有效的方法,將這種少樣本學習能力轉移到多模態(視覺和語言)設置中。利用對齊的圖像和語言標註數據,我們訓練一個視覺編碼器,將每個圖像表示為一系列連續的嵌入,以便預先訓練的凍結語言模型在提示這個前綴後生成適當的標註。在結果中,一個多模態少樣本學習器,當有範例時,它可以有驚人的能力學習各種新任務,這些範例被表示為多個交錯的圖像和文本嵌入序列。另外我們展示它能快速學習新物件和新視覺類別的詞彙,只需少量範例即可進行視覺問答,並能利用外部知識,在多個已建立和新的基準測試中測試單一模型的表現。
- 論文連結:https://arxiv.org/pdf/2106.13884.pdf
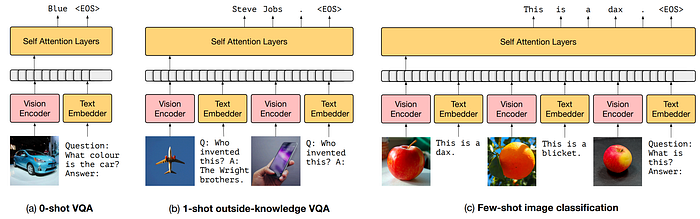
21. ALBEF
- 論文名稱:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- 發布時間:2021/07/16
- 發布單位:Salesforce
- 簡單摘要:在文字和圖像embedding合起來前,先用對比學習對齊
- 閱讀重點:Architecture、Image-Text Contrastive Learning、masked language modeling、Image-Text Matching、Momentum Distillation
- 中文摘要:大規模的視覺與語言表徵學習在各種視覺與語言任務上顯示出了顯著的改進希望。現有的方法大多使用基於Transformer的多模式編碼器來共同建模視覺標記(基於區域的圖像特徵)和詞語標記。但是由於視覺標記和詞語標記不是對齊的,對多模式編碼器來說學習圖像和文本之間的交互作用是具有挑戰性的。所以本文介紹了一種對齊圖像和文本表示後再通過跨模態注意力進行融合的對比損失方法,稱為ALBEF,這有助於更有根據的視覺與語言表徵學習。另外與大多數現有方法不同的是,我們的方法不需要邊界框標註或高分解析度的圖像。為了提高從充滿雜訊的網路數據中學習的效果,我們提出了動量蒸餾,一種從動量模型生成的虛擬目標進行自我訓練的方法。從最大化共同訊息的角度對ALBEF進行了理論分析,顯示了不同的訓練任務可以解釋為為圖像-文本對生成不同視角的方式。而ALBEF在多個視覺與語言下游任務上實現了最先進的性能。在圖像-文本檢索方面,ALBEF優於那些在數量級更大的數據集上進行預訓練的方法。在視覺問答和NLVR2方面,ALBEF相對於最先進方法,在分別達到了2.37%和3.84%的改進,同時具有更快的推理速度。
- 論文連結:https://arxiv.org/pdf/2107.07651.pdf
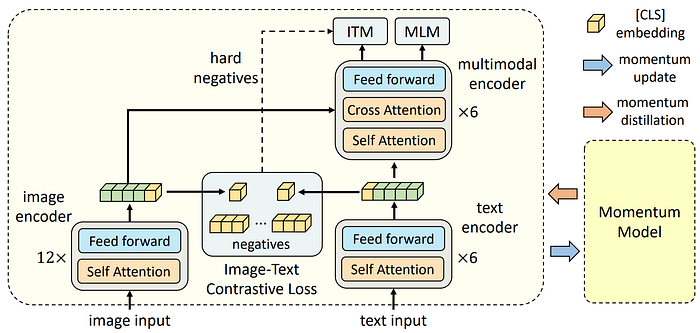
22. CoOp
- 論文名稱:Learning to Prompt for Vision-Language Models
- 發布時間:2021/09/02
- 發布單位:南洋理工大學
- 簡單摘要:引入可學習的prompt,讓VLM更好的適應下游任務
- 閱讀重點:Models、Zero-Shot Inference、Context Optimization、Unified Context、Class-Specific Context
- 中文摘要:大型預訓練的視覺語言模型(如CLIP)展示了在各種後續任務中學習可遷移式的表徵潛力。與傳統基於離散標註的表徵學習不同,視覺語言預訓練將圖像和文本對齊在一個共同的特徵空間中,允許通過提示(prompt)進行零樣本遷移到後續任務,即從描述感興趣類別的自然語言中合成分類權重。所以在這項工作中,我們討論了實際部署這種模型的主要挑戰是提示工程,它需要領域專業知識並且非常耗時,因為我們只要稍微更改措辭,就可能對性能產生巨大影響,所以需要花費大量時間進行詞語調整。受自然語言處理(NLP)中最近提示學習研究的啟發,我們提出了「上下文優化」(CoOp),其一種簡單的方法,專門用於適應類似CLIP的視覺語言模型進行後續圖像識別。具體而言,CoOp通過可學習的向量來建模提示的上下文詞,同時保持整個預訓練參數不變。為應對不同的圖像識別任務,我們提供了兩種CoOp的實現:統一上下文和類別特定上下文。最後通過對11個數據集的大量實驗,我們展示CoOp只需一兩個範例即可超過手工提示的表現,並且使用更多範例時,能顯著改進提示工程,例如使用16個範例時,平均改進幅度約為15%(最高可達45%以上)。儘管其是一種基於學習的方法,CoOp在與使用手工提示的零樣本模型相比的領域通用性表現上具有出色的性能。
- 論文連結:https://arxiv.org/pdf/2109.01134.pdf
23. WiSE-FT
- 論文名稱:Robust fine-tuning of zero-shot models
- 發布時間:2021/09/04
- 發布單位:華盛頓大學、OpenAI、哥倫比亞大學、Google
- 簡單摘要:探討微調zero-shot模型領域偏移問題
- 閱讀重點:Distribution shifts、Effective robustness、Zero-shot models、Standard fine-tuning、Weight-space ensembling
- 中文摘要:大型預訓練模型如CLIP或ALIGN在進行zero-shot推論時(即不對特定數據集進行微調)能夠保持穩定的準確度。儘管現有的微調方法能夠顯著提高對特定目標數據分佈的準確性,但往往會降低對分佈變化的穩定性。所以為了解決這一矛盾,我們引入了一種簡單有效的方法,讓我們在微調時提高穩定性:將zero-shot和微調模型的權重進行整合(WiSE-FT)。與標準微調相比,WiSE-FT在分佈變化下提供了大幅提高的準確度,同時保持了對目標分佈的高準確性。在ImageNet和衍生的五種分佈變化下,WiSE-FT提高了4至6個百分點(pp)的分佈變化下準確度,同時提高了1.6個pp的ImageNet準確度。在另外六種分佈變化下,WiSE-FT的穩定性提升同樣巨大(2至23個pp),在七個常用的遷移式學習數據集上,與標準微調相比,準確度提升了0.8至3.3個pp。這些改進在微調或推論過程中不會增加額外的計算成本。
- 論文連結:https://arxiv.org/pdf/2109.01903.pdf
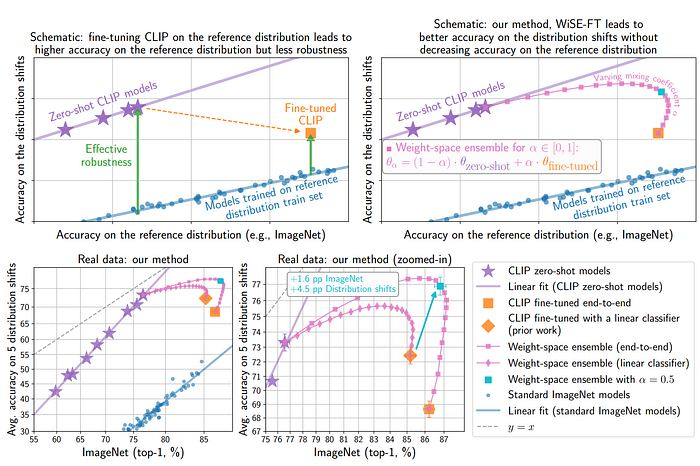
24. PICa
- 論文名稱:An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
- 發布時間:2021/09/10
- 發布單位:Microsoft
- 簡單摘要:將圖像表示成文字,把GPT-3當成知識庫來prompt
- 閱讀重點:GPT-3 for In-context Learning、GPT-3 for VQA、In-context Examples、In-context example selection、Multi-query ensemble
- 中文摘要:基於知識的視覺問答(VQA)涉及回答需要圖像中不存在外部知識的問題。對於現有方法是首先從外部資源檢索知識,然後在選定的知識、輸入圖像和問題之間進行推理以進行答案預測。但是這種兩個步驟的方法可能導致不匹配的問題,潛在地限制了VQA的性能。例如檢索到的知識可能存在雜訊且與問題無關,而在推理過程中重新嵌入的知識特徵可能偏離知識庫(KB)中的原始含義。所以為了解決這個挑戰,我們提出了PICa,一種簡單而有效的方法,通過使用圖像標題(或標註)來提示GPT3,用於基於知識的VQA中。受GPT-3在知識檢索和問答方面的能力啟發,我們不像以前的工作那樣使用結構化的知識庫,而是將GPT-3視為一個隱式且無結構的知識庫,可以共同獲取和處理相關知識。具體而言,我們首先將圖像轉換為GPT-3能夠理解的標題(或標註),然後通過提供一些上下文的VQA範例,以少量範例方式使GPT-3適應解決VQA任務。我們進一步通過仔細研究:(i)哪種文本格式最能描述圖像內容,以及(ii)如何更好地選擇和使用上下文範例來提高性能,讓PICa首次解鎖了GPT-3在多模態任務中的應用。最後我們僅使用16個範例,就可以讓PICa在OK-VQA數據集上比監督學習的最新技術提高了絕對+8.6分。我們還在VQAv2上對PICa進行了基準測試,其中PICa也展示了不錯的少量範例性能。
- 論文連結:https://arxiv.org/pdf/2109.05014.pdf
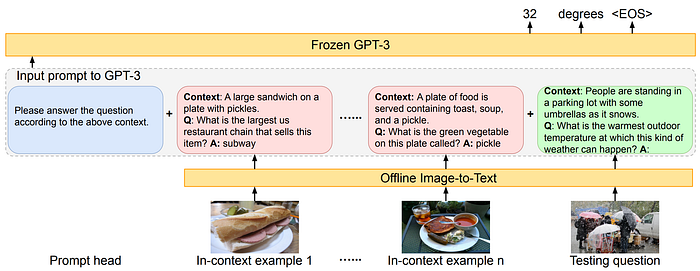
25. CLIP-Adapter
- 論文名稱:CLIP-Adapter: Better Vision-Language Models with Feature Adapters
- 發布時間:2021/10/09
- 發布單位:Shanghai AI Lab、羅格斯大學、香港中文大學
- 簡單摘要:把CLIP上面加上adapter來做PEFT
- 閱讀重點:Classifier Weight Generation、CLIP-Adapter、Bottleneck Layer、Context Optimization
- 中文摘要:大規模對比式視覺語言預訓練在視覺表徵學習上取得了重大進展。相較於傳統的固定離散標註的視覺系統,CLIP直接在開放詞彙的情境下學習將圖像與原始文本進行對齊。在後續任務中,使用精心選擇的文本提示進行零樣本預測。為避免複雜的提示工程,CoOp提出了上下文優化方法,用少樣本學習連續向量作為特定任務的提示。而在這篇論文中,我們展示了另一種實現更好視覺語言模型的替代方法,與提示調整不同,我們提出了CLIP-Adapter,在視覺或語言分支上使用特徵適配器進行微調。具體來說,CLIP-Adapter採用了額外的瓶頸層來學習新特徵,並將原始預訓練特徵與剩餘風格的特徵混合。結果顯示,CLIP-Adapter能夠優於上下文優化,同時保持簡單的設計。在各種視覺分類任務上的實驗和廣泛的消融研究證實了我們方法的有效性。
- 論文連結:https://arxiv.org/pdf/2110.04544.pdf
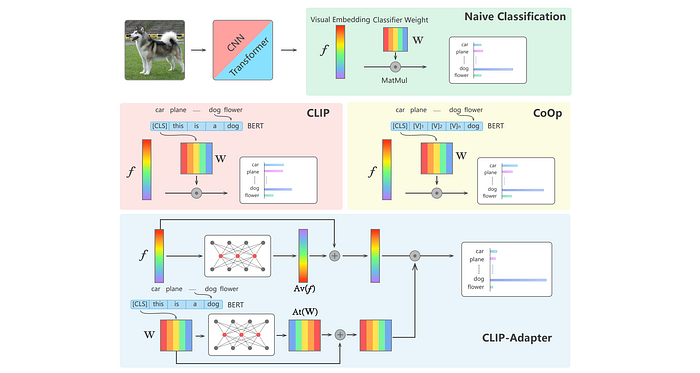
26. DeCLIP
- 論文名稱:Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
- 發布時間:2021/10/11
- 發布單位:商湯科技、德州大學奧斯汀分校、雪梨大學
- 簡單摘要:原本的CLIP需要太多資料訓練,弄個Data efficient版本的吧
- 閱讀重點:CLIP、Self-Supervision within each modality、Multi-View Supervision、Nearest-Neighbor Supervision
- 中文摘要:最近大規模的對比語言-圖像預訓練(CLIP)因其出色的零樣本識別能力和優異的可遷移性引起了前所未有的關注。但是CLIP需要4億個圖像-文本配對來進行預訓練,因此具有極大的數據需求,限制了其應用。所以這份工作提出了一種新的訓練範式,名為“高效數據使用的CLIP(DeCLIP)”,以解決這個限制。我們展示了通過精心利用圖像-文本配對中的普遍監督,我們的DeCLIP可以更有效地學習通用的視覺特徵。我們不僅僅使用單一的圖像-文本對比監督,還充分利用了數據潛力,包括(1)在每個模式內部的自我監督;(2)跨模式的多視圖監督;(3)來自其他相似配對的最近鄰監督。受益於內在監督,我們的DeCLIP-ResNet50在ImageNet上可以達到60.4%的零樣本Top1準確率,比CLIP-ResNet50高出0.8%,且使用的數據量只有其7.1倍。我們的DeCLIP-ResNet50在轉移到下游任務時,在11個視覺數據集中有8個中表現優於對應的模型。此外在我們的框架中,模型的擴展和計算規模也表現出良好的效果。
- 論文連結:https://arxiv.org/pdf/2110.05208.pdf
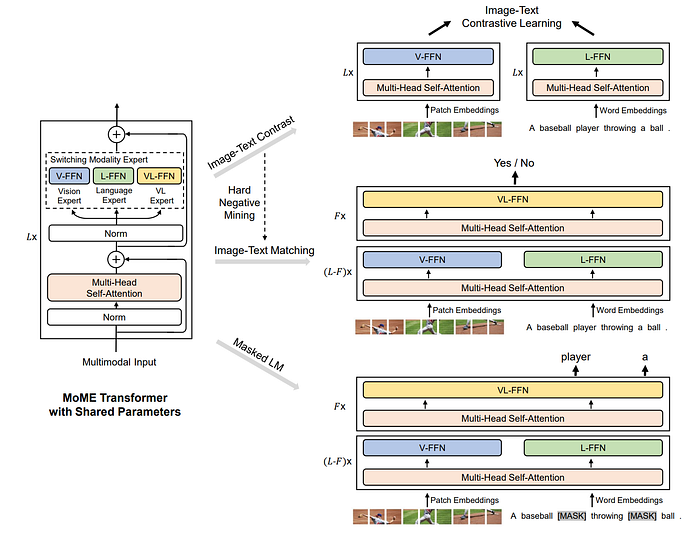
27. VLMo
- 論文名稱:VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
- 發布時間:2021/11/03
- 發布單位:Microsoft
- 簡單摘要:基於混和專家MoE的視覺語言模型
- 閱讀重點:Mixture-of-Modality-Experts Transformer、Pre-Training Tasks、Stagewise Pre-Training、Fine-Tuning VLMO
- 中文摘要:我們提出了一個統一的視覺-語言預訓練模型(VLMo),它同時學習雙編碼器和融合編碼器,並使用模塊化Transformer網絡。具體而言,我們引入了模態混合專家(MoME)Transformer,其中每個區塊包含一組模態特定專家和一個共享的自注意力層。由於MoME的建模靈活性,預訓練的VLMo可以作為視覺-語言分類任務的融合編碼器進行微調,也可以作為高效的圖像-文本檢索的雙編碼器使用。此外我們也提出了一種分階段的預訓練策略,其可有效利用了大規模的僅有圖像和僅有文本的數據。最後實驗結果顯示,VLMo在各種視覺-語言任務中取得了最先進的成果,包括VQA、NLVR2和圖像-文本檢索。
- 論文連結:https://arxiv.org/pdf/2111.02358.pdf
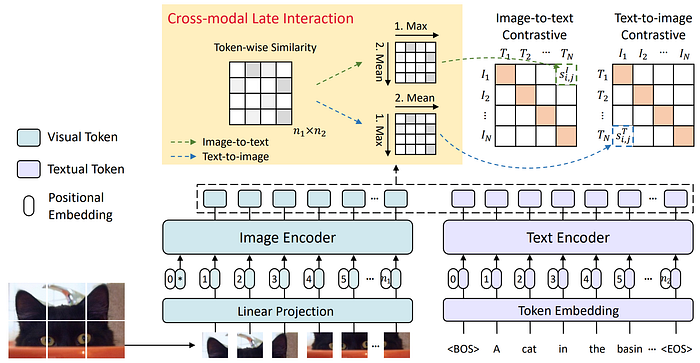
28. FILIP
- 論文名稱:FILIP: Fine-grained Interactive Language-Image Pre-Training
- 發布時間:2021/11/09
- 發布單位:華為、香港科技大學、中山大學
- 簡單摘要:透過跨模態後期互動機制實現更細粒度的對齊
- 閱讀重點:Fine-grained contrastive learning、cross-modal late interaction、Prompt Ensemble and Templates、Augmentation
- 中文摘要:這篇論文著重於無監督大規模視覺語言預訓練,展示了在多種下游任務上的潛在優勢。現有方法通常通過模擬每種模式的全局特徵相似性,或者更精細的跨模態交互作用,使用視覺和文本標註上的交叉/自注意力,但是這些方法在訓練和推理效率方面效果不佳。所以本文提出了一種大規模細粒度交互式語言-圖像預訓練(FILIP),通過一種跨模態的後期交互機制實現更精細的對齊。它使用視覺和文本標註之間的最大相似性來引導對比目標,成功地利用了圖像區塊和文本詞語之間更精細的表達性。另外FILIP僅通過修改對比損失便可提高性能,同時具有在推理時離線預先計算圖像和文本表徵的能力,從而保持大規模訓練和推理的高效性。此外我們建立了一個名為FILIP300M的新大規模圖像-文本對數據集進行預訓練。實驗結果中,FILIP在多個下游視覺語言任務上取得了最先進的性能,包括零樣本圖像分類和圖像-文本檢索。對於詞塊對齊的可視化進一步顯示了FILIP可以學習有意義的細粒度特徵,具有有潛力的定位能力。
- 論文連結:https://arxiv.org/pdf/2111.07783.pdf
29. LiT
- 論文名稱:LiT: Zero-Shot Transfer with Locked-image text Tuning
- 發布時間:2021/11/15
- 發布單位:Google
- 簡單摘要:把圖像encoder鎖住,只去tune文字encoder
- 閱讀重點:Contrastive pre-training、Contrastive-tuning、Locked-image Tuning
- 中文摘要:這篇論文介紹了一種名為對比調整(contrastive-tuning)的簡單方法,利用對比訓練來對齊圖像和文字模型,同時仍然利用它們的預訓練。在實證研究中,我們發現鎖定預訓練圖像模型並解鎖文字模型效果最佳。我們稱這種對比調整為「鎖定圖像調整」(LiT),只需教導文字模型如何從預訓練的圖像模型中獲取新任務的良好表徵。另外LiT 模型具有對新視覺任務的零樣本遷移能力,例如圖像分類或檢索。這個方法可廣泛且可靠地適用於多種預訓練方法(監督和非監督)以及不同架構(ResNet、Vision Transformers 和 MLP-Mixer),使用三個不同的圖像-文字數據集。最後利用基於Transformer的預訓練ViT-g/14模型,在ImageNet測試集上實現了85.2%的零樣本遷移準確度,並在具有挑戰性的ObjectNet測試集上達到了82.5%的準確度。
- 論文連結:https://arxiv.org/pdf/2111.07991.pdf

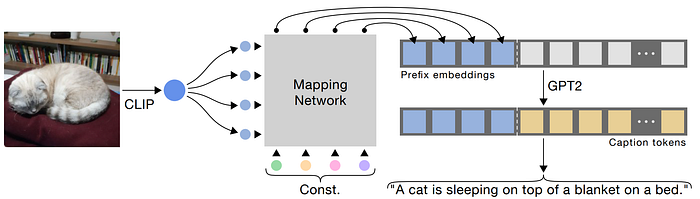
30. CLIPCap
- 論文名稱:ClipCap: CLIP Prefix for Image Captioning
- 發布時間:2021/11/18
- 發布單位:臺拉維夫大學
- 簡單摘要:我只要訓練映射網路把CLIP Embedding映射到GPT-2就好
- 閱讀重點:Language model fine-tuning、Mapping Network Architecture、Inference
- 中文摘要:這篇論文討論了圖像標題生成,其為視覺與語言理解中的基本任務,模型會為給定的圖像預測一個訊息豐富的文字描述。對於此我們提出了一個簡單的方法來應對這個任務。我們使用CLIP編碼作為標題的前綴,通過使用一個簡單的映射網路,然後對語言模型進行微調以生成圖像標題。在最近提出的CLIP模型包含豐富的語義特徵,其通過文本上下文進行訓練的,非常適合視覺與語言感知。所以我們的關鍵想法是,與預訓練的語言模型(GPT2)一起,我們可以廣泛理解視覺和文本數據。因此我們的方法只需要相當快速的訓練,就能生成一個有競爭力的標題生成模型。而在沒有額外標註或預訓練的情況下,它能高效地為大規模和多樣化的數據集生成有意義的標題。令人驚訝的是,即使只有映射網路被訓練,方法也能良好運作,而CLIP和語言模型都保持凍結,這使得架構更輕便,可訓練的參數更少。最後通過量化評估,我們展示了我們的模型在具有挑戰性的Conceptual Captions和nocaps數據集上取得了與最先進方法相當的結果,同時更加簡單、快速和輕巧。
- 論文連結:https://arxiv.org/pdf/2111.09734.pdf
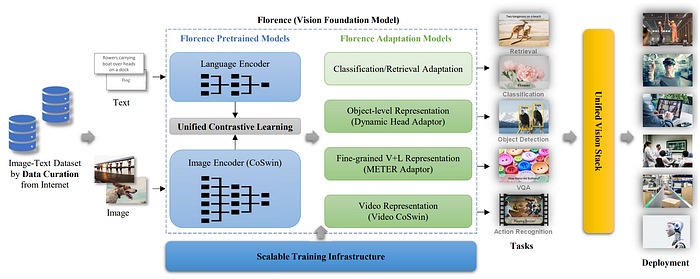
31. Florence
- 論文名稱:Florence: A New Foundation Model for Computer Vision
- 發布時間:2021/11/22
- 發布單位:Microsoft
- 簡單摘要:把視覺任務擴展到空間-時間-模態三個面向訓練基礎模型
- 閱讀重點:Unified Image-Text Contrastive Learning、Florence 、Object-level Visual & Fine-Grained V+L Representation Learning
- 中文摘要:我們日常多元開放的視覺世界需要電腦視覺模型能夠以最小程度的定制化快速泛化,就如同人類的視覺一樣。所以電腦視覺基礎模型變得至關重要,這些模型通常是在多樣、大規模數據集上訓練的,能夠適應各種不同的下游任務。在現有的基礎視覺模型(例如CLIP、ALIGN和Wu Dao 2.0)主要將圖像和文字表徵映射到跨模態共享表徵的基礎上,所以我們推出了一個新的電腦視覺基礎模型 — Florence。Florence從粗(場景)到細(物體)、靜態(圖像)到動態(影片)、從RGB到多種模式(標題、深度),擴展了其表徵。通過吸收網路規模的圖像-文本數據中的通用視覺-語言表徵,Florence模型可輕鬆適應應於各種電腦視覺任務,如分類、檢索、物體檢測、視覺問答、圖像標題、影片檢索和動作識別。此外Florence在多種遷移式學習中表現出色,包括完全採樣的微調、線性探測、少樣本和對新圖像、新物體的零標註遷移。所有的這些特性對於我們的視覺基礎模型來說都至關重要,以滿足廣泛的視覺任務。最後Florence在44個代表性基準測試中取得了新的最先進結果,例如在ImageNet-1K零標籤分類上,Top-1準確率達到83.74,Top-5準確率達到97.18,在COCO微調上達到62.4的mAP,在VQA上達到80.36,在Kinetics-600上達到87.8。
- 論文連結:https://arxiv.org/pdf/2111.11432.pdf
32. DenseCLIP
- 論文名稱:DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
- 發布時間:2021/12/02
- 發布單位:北京清華大學、PhiGent Robotics
- 簡單摘要:將CLIP和prompt模式用到dense任務,如分割、目標偵測上
- 閱讀重點:Language-Guided Dense Prediction、Context-Aware Prompting、Instantiations
- 中文摘要:近期的進展顯示,利用對比的圖像-文本對進行大規模預訓練,是從自然語言監督中學習高品質視覺表徵的一個有前景的替代方法。這種新範式受益於更廣泛的監督來源,在下游分類任務和數據集中展現出令人印象深刻的可遷移性。但是將從圖像-文本對中學到的知識遷移到更複雜的密集預測任務問題幾乎未被探討。所以在這項工作中,我們提出了一個新的密集預測框架,通過隱式和顯式地利用來自CLIP的預訓練知識。具體來說,我們將CLIP中的原始圖像-文本匹配問題轉換為像素-文本匹配問題,並使用像素-文本分數圖來引導密集預測模型的學習。通過進一步利用圖像中的上下文訊息提示語言模型,我們能夠促進模型更好地利用預訓練知識。另外我們的方法與模型無關,可以應用於任意的密集預測系統和各種預訓練的視覺架構,包括CLIP模型和ImageNet預訓練模型。大量實驗證明了我們方法在語義分割、物體檢測和實例分割任務上的卓越性能。
- 論文連結:https://arxiv.org/pdf/2112.01518.pdf
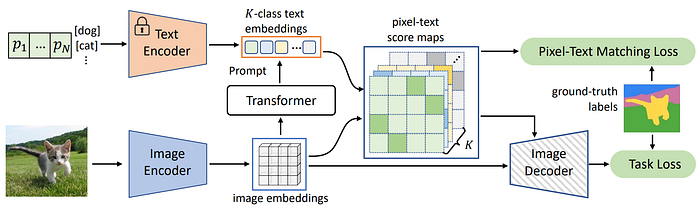
33. MaskCLIP
- 論文名稱:Extract Free Dense Labels from CLIP
- 發布時間:2021/12/02
- 發布單位:南洋理工大學、Shanghai AI Lab
- 簡單摘要:不用標註和微調,我也可以把CLIP用在影像分割上
- 閱讀重點:Conventional Fine-Tuning Hinders Zero-Shot Ability、MaskCLIP、Key Smoothing and Prompt Denoising、MaskCLIP+
- 中文摘要:CLIP(對比式語言-圖像預訓練)在開放詞彙的zero-shot圖像識別方面取得了顯著的突破。許多最近的研究利用了預訓練的CLIP模型進行圖像級別的分類和操作。 所以本文旨在探討CLIP在像素級密集預測,尤其是語義分割方面的潛力。通過輕微修改,我們展示了MaskCLIP在各種數據集上在沒有標註和微調的情況下對開放概念達到非常好的分割結果。通過添加虛假標記和自我訓練,MaskCLIP+在PASCAL VOC/PASCAL Context/COCO Stuff等數據集上超越了目前最先進的zero-shot語義分割方法,例如未見類別的mIoU從35.6/20.7/30.3提高到了86.1/66.7/54.7。我們還測試了MaskCLIP在輸入失真下的穩定性,並評估它在區分細粒度對象和新概念方面的能力。最後研究結果顯示,MaskCLIP可以成為密集預測任務的新可靠監督來源,實現無標註的分割。
- 論文連結:https://arxiv.org/pdf/2112.01071.pdf
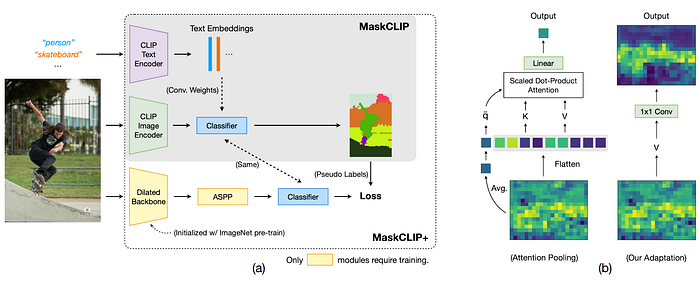
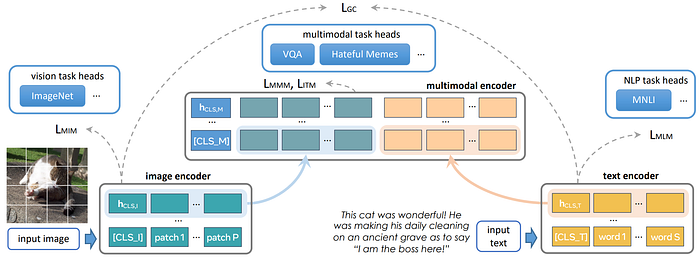
34. FLAVA
- 論文名稱:FLAVA: A Foundational Language And Vision Alignment Model
- 發布時間:2021/12/08
- 發布單位:Facebook(Meta)
- 簡單摘要:MMM、MIM、MLM全部整合在一起
- 閱讀重點:model architecture、Multimodal pretraining objectives、Unimodal pretraining objectives、Public Multimodal Datasets
- 中文摘要:這篇論文討論了最先進的視覺和視覺語言模型,它們依賴大規模的視覺和語言預訓練,以在各種下游任務中獲得良好的表現。通常這些模型可能是跨模態(對比性)或多模態(早期融合),但兩者並不兼具;它們通常只針對特定的模式或任務。所以一個有前途的方向是使用一個全面的通用模型作為“基礎”,同時針對所有模式,一個真正的視覺和語言基礎模型,應該擅長視覺任務、語言任務以及跨模態和多模態的視覺和語言任務。所以我們提出了FLAVA作為這樣一個模型,並展示了在涵蓋這些目標模式的35個任務上出色的表現。
- 論文連結:https://arxiv.org/pdf/2112.04482.pdf
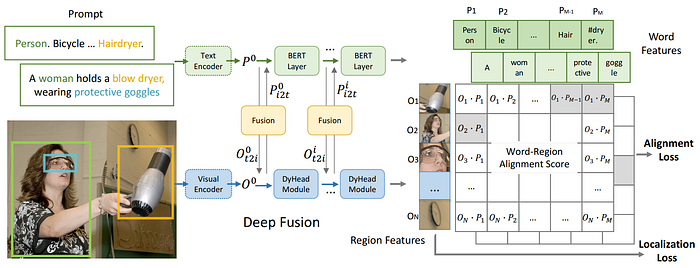
35. GLIP
- 論文名稱:Grounded Language-Image Pre-training
- 發布時間:2021/12/07
- 發布單位:加州大學洛杉磯分校、Microsoft、華盛頓大學
- 簡單摘要:統一object detection和phrase grounding任務
- 閱讀重點:Equivalence between detection and grounding、Language-Aware Deep Fusion、Pre-training with Scalable Semantic-Rich Data
- 中文摘要:這篇論文介紹了一個名為GLIP的模型,用於學習物件級別、具有語言感知和豐富語義的視覺表徵。GLIP結合了物件檢測和短語對齊作為預訓練的基礎。這個結合有兩個好處:1)GLIP能夠從檢測和對齊的資料中學習,改善兩個任務並啟動一個良好的對齊模型;2)GLIP能夠通過自我訓練的方式利用大量的圖像文本對來生成對齊框,使所學表徵具有豐富的語義。在實驗中,我們用2700萬的對齊資料對GLIP進行了預訓練,其中包括300萬人工標註和2400萬網絡爬取的圖像文本對。學到的表示在各種物件級別識別任務中展示了強大的零樣本和少樣本遷移能力。1)在直接在COCO和LVIS上評估時(在預訓練期間未看到任何COCO圖像),GLIP分別達到了49.8和26.9的平均精度(AP),超過了許多監督基準。2)在對COCO進行微調後,GLIP在驗證集上達到了60.8的AP,在測試集上達到了61.5的AP,超越了之前的最佳結果。3)當轉移到13個下游物件檢測任務時,一個1-shot的GLIP模型與全監督的Dynamic Head模型表現相當。
- 論文連結:https://arxiv.org/pdf/2112.03857.pdf
36. RegionCLIP
- 論文名稱:RegionCLIP: Region-based Language-Image Pretraining
- 發布時間:2021/12/16
- 發布單位:威斯康辛大學麥迪遜分校、Microsoft
- 簡單摘要:讓CLIP能學習區域等級的視覺表徵,達到更好的alignment
- 閱讀重點:Visual and Semantic Region Representation、Visual-Semantic Alignment for Regions、Transfer Learning
- 中文摘要:對比式語言-圖像預訓練(CLIP)利用圖像與文字對在零標籤和遷移式學習環境下,已在圖像分類方面取得了令人印象深刻的成果。但是我們發現直接將此類模型應用於圖像區域的物體檢測時表現不佳,原因是存在領域偏移,也就是CLIP是訓練用於將整個圖像與文字描述進行匹配,但卻無法捕捉圖像區域與文字片段之間的細微對應。所以為了解決此問題,我們提出了一種新方法稱為RegionCLIP,它將CLIP顯著擴展至學習區域級別的視覺表徵,從而實現圖像區域和文字概念之間的精細對齊。我們的方法利用CLIP模型將圖像區域與模板標題進行匹配,然後對我們的模型進行預訓練,以在特徵空間中對齊這些區域-文字對。當將我們的預訓練模型轉移到開放詞彙的物體檢測任務時,我們的方法在COCO和LVIS數據集中,對於新類別分別顯著優於當前最先進的方法3.8 AP50和2.2 AP。此外所學的區域表徵支持物體檢測的零樣本推斷,在COCO和LVIS數據集上展示了令人期待的結果。
- 論文連結:https://arxiv.org/pdf/2112.09106.pdf
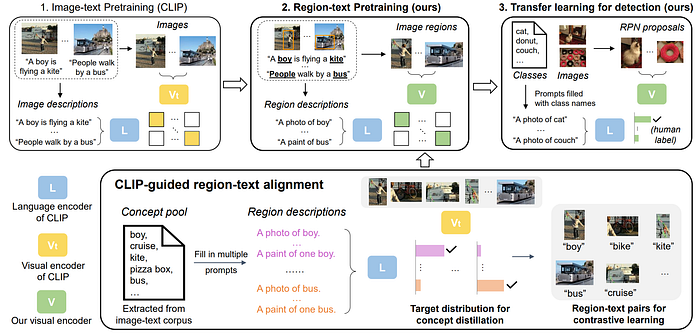
37. SLIP
- 論文名稱:SLIP: Self-supervision meets Language-Image Pre-training
- 發布時間:2021/12/23
- 發布單位:加州大學柏克萊分校、Facebook(Meta)
- 簡單摘要:把CLIP結合自監督學習來做多任務學習
- 閱讀重點:Contrastive Language-Image Pre-training、Image Self-Supervision、SLIP Framework、Improved Training Procedure
- 中文摘要:這項最新研究表明,自我監督的預訓練在具有挑戰性的視覺識別任務上優於監督學習。CLIP是一種嶄新的以語言監督學習的方法,在各種基準測試中展現了令人振奮的性能。所以在這份研究中,我們探討了自我監督學習是否能夠幫助語言監督用於視覺表示學習,並提出了SLIP,這是一種將自我監督學習和CLIP預訓練結合的多任務學習框架。在使用Vision Transformers進行預訓練後,我們全面評估了表徵的品質,並將性能與CLIP和自我監督學習在三種不同設置下進行了比較:零樣本遷移、線性分類和端對端微調。在ImageNet和一系列其他數據集上,我們發現SLIP大幅提高了準確性。我們進一步通過不同模型大小、訓練計劃和預訓練數據集的實驗驗證了我們的結果。我們的研究發現顯示,SLIP兼具兩者的優勢:在線性準確性方面優於自我監督(+8.1%),在零樣本準確性方面優於語言監督(+5.2%)。
- 論文連結:https://arxiv.org/pdf/2112.12750.pdf
38. Detic
- 論文名稱:Detecting Twenty-thousand Classes using Image-level Supervision
- 發布時間:2022/01/07
- 發布單位:Facebook(Meta)、德州大學奧斯汀分校
- 簡單摘要:訓練detector的classifiers,讓他學會更多字彙量
- 閱讀重點:Open-vocabulary object detection、Non-prediction-based losses、Relation to prediction-based assignments
- 中文摘要:Detic是一種我們提出的物件偵測方法,它通過在影像分類數據上訓練偵測器的分類器,從而將偵測器的詞彙擴展到數以萬計的概念。與以往方法不同,Detic不需要複雜的分配方案,這讓實施變得更加容易,並且與多種偵測架構和基礎兼容。我們的結果顯示,Detic即使對於沒有框標註的類別,也能產生出優秀的偵測器。在開放詞彙和長尾偵測基準上,Detic的表現優於以往的方法。在開放詞彙的LVIS基準上,Detic在所有類別上提升了2.4 mAP,在新類別上提升了8.3 mAP。在標準的LVIS基準上,Detic在所有類別或僅稀有類別上的mAP為41.7,因此彌補了樣本稀少的物件類別的性能差距。我們首次使用ImageNet數據集的所有二萬一千個類別進行偵測器訓練,並展示它在新數據集上的泛化能力,而無需進行微調。
- 論文連結:https://arxiv.org/pdf/2201.02605.pdf

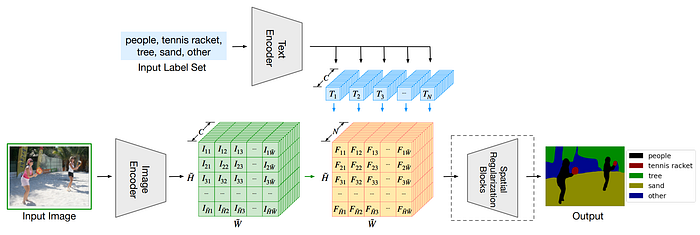
39. LSeg
- 論文名稱:Language-driven Semantic Segmentation
- 發布時間:2022/01/10
- 發布單位:康乃爾大學、哥本哈根大學、Apple、Intel
- 簡單摘要:把物件文字標籤和圖片像素對齊,來做語言驅動影像分割
- 閱讀重點:Text encoder、Image encoder、Word-pixel correlation tensor、Spatial regularization、Training details
- 中文摘要:我們提出了一種新的模型LSeg,用於語言驅動的語義圖像分割。LSeg使用文本編碼器計算描述性輸入標籤的嵌入(例如“草”或“建築”),同時還使用基於Transformer的圖像編碼器計算輸入圖像的每個像素的密集嵌入。圖像編碼器通過對比目標進行訓練,將像素嵌入對齊到相應語義類別的文本嵌入。文本嵌入提供了一種靈活的標籤表示,其中語義上相似的標籤在嵌入空間中映射到相似的區域(例如“貓”和“毛茸茸”)。這使得LSeg能夠在測試時泛化到以前未見過的類別,而無需重新訓練甚至不需要一個額外的訓練樣本。我們展示了我們的方法在零樣本和少樣本語義分割方法方面具有極具競爭力的性能,甚至在提供固定標籤集時,也能與傳統分割算法的準確度相匹配。
- 論文連結:https://arxiv.org/pdf/2201.03546.pdf
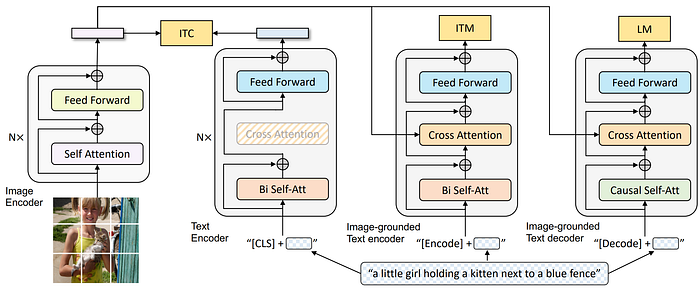
40. BLIP
- 論文名稱:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 發布時間:2022/01/28
- 發布單位:Salesforce
- 簡單摘要:統一多模態模型理解很生成任務
- 閱讀重點:Unimodal encoder、Image-grounded text encoder、Image-grounded text decoder、ITC、ITM、LM、CapFilt
- 中文摘要:Vision-Language Pre-training (VLP)提升了許多視覺語言任務的表現。但是大多數現有的預訓練模型在理解型任務或生成型任務中只表現出色於其中一方。此外通過從網路收集的雜訊圖像文本,對來擴展數據集來提高性能,不是一個最優的監督來源。所以在本文中,我們提出了BLIP,一個新的VLP框架,可以靈活應用於視覺語言理解和生成任務。BLIP通過啟動標題來有效利用含有察遜的網路數據,其中一個標題生成器產生合成標題,一個過濾器則刪除雜訊。最後我們在各種視覺語言任務上取得了最先進的成果,例如圖像文本檢索(平均召回率@1增加了2.7%)、圖像標題生成(CIDEr提高了2.8%)、以及視覺問答(VQA分數提高了1.6%)。在零樣本遷移至影片語言任務時,BLIP還展現了強大的泛化能力。
- 論文連結:https://arxiv.org/pdf/2201.12086.pdf
41. OFA
- 論文名稱:OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
- 發布時間:2022/02/07
- 發布單位:阿里巴巴
- 簡單摘要:不管單模態還是多模態,通通統一成seq2seq來預訓練
- 閱讀重點:I/O & Architecture、Tasks & Modalities、Pretraining Datasets、Training & Inference、Scaling Models
- 中文摘要:這項研究致力於打破複雜任務/模態特定定制的架構,並追求一個統一的多模態預訓練範式。所以我們提出了OFA,一個支持任務全面性的任務無關和模態無關框架。OFA在簡單的序列到序列學習框架中統一了各種跨模態和單模態任務,包括圖像生成、視覺 grounding、圖像標註、圖像分類、語言建模等。OFA在預訓練和微調階段都遵循基於指令的學習,對於下游任務不需要額外的任務特定層。與依賴極大跨模態數據集的最新視覺和語言模型相比,OFA僅在2000萬個公開可用的圖像文本對上進行了預訓練。儘管它的簡單性和相對小規模的訓練數據,OFA在一系列跨模態任務上取得了新的最優成績,同時在單模態任務上表現出高競爭力。我們進一步的分析表明,OFA還可以有效地適用於未見過的任務和未見過的領域。
- 論文連結:https://arxiv.org/pdf/2202.03052.pdf

42. GroupViT
- 論文名稱:GroupViT: Semantic Segmentation Emerges from Text Supervision
- 發布時間:2022/02/22
- 發布單位:加州大學聖地亞哥分校、Nvidia
- 簡單摘要:可以學習任何形狀的表徵,並且只用文字監督訓練
- 閱讀重點:Grouping Vision Transformer、Learning from Image-Text Pairs、Zero-Shot Transfer to Semantic Segmentation
- 中文摘要:這篇論文討論了視覺場景理解中的分組和識別,例如對象檢測和語義分割。在端到端的深度學習系統中,圖像區域的分組通常是通過從像素級別的識別標籤獲得的自上而下的監督來隱式地實現的。但在這篇論文中,我們提議將分組機制重新引入深度網絡,使得僅通過文本監督就能自動生成語義區段。所以我們提出了一種分層分組視覺Transformer(GroupViT),它超越了常規的網格結構表徵,學習將圖像區域分組成逐漸更大的任意形狀段落。我們使用對比損失函數在大規模圖像-文字數據集上聯合訓練GroupViT和文本編碼器。GroupViT僅通過文本監督,在沒有任何像素級標註的情況下,學會了將語義區域分組在一起,並成功地以零微調方式遷移到語義分割任務中。它在PASCAL VOC 2012數據集上實現了52.3%的零微調mIoU準確度,在PASCAL Context數據集上實現了22.4%的mIoU,並與需要更高級別監督最先進的遷移式學習方法競爭。
- 論文連結:https://arxiv.org/pdf/2202.11094.pdf
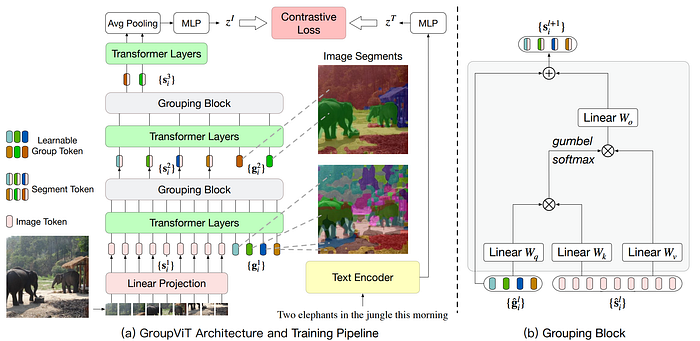
43. CoCoOp
- 論文名稱:Conditional Prompt Learning for Vision-Language Models
- 發布時間:2022/03/10
- 發布單位:南洋理工大學
- 簡單摘要:在CoOp上加入meta-net,生成條件標記,讓泛化能力更好
- 閱讀重點:Contrastive Language-Image Pre-training、Context Optimization、Conditional Context Optimization
- 中文摘要:強大的預訓練視覺語言模型(例如CLIP)的崛起使得探索如何適應這些模型到下游數據集變得至關重要。最近提出的一種名為上下文優化(CoOp)的方法引入了提示學習的概念,這是自然語言處理中的一個新趨勢,將其應用於預先訓練的視覺語言模型。具體而言,CoOp將提示中的上下文詞轉換為一組可學習的向量,僅使用少量標記的圖像進行學習,就可以比經過精心調整的手動提示獲得巨大改進。但是我們的研究發現CoOp的一個關鍵問題,就是所學的上下文無法泛化到同一數據集中更廣泛的未見類別,這代表CoOp在訓練期間過度擬合了觀察到的基本類別。所以為解決此問題,我們提出了有條件的上下文優化(CoCoOp),它通過進一步學習一個輕量級神經網絡,為每個圖像生成一個依賴輸入的條件標記(向量)。與CoOp的靜態提示相比,我們的動態提示能夠適應每個實例,因此對類別變化的敏感度較低。大量實驗表明,CoCoOp相比CoOp更好地泛化到未見類別,甚至展現出在單個數據集之外更好的遷移性;同時也具有更強的領域泛化性能。
- 論文連結:https://arxiv.org/pdf/2203.05557.pdf
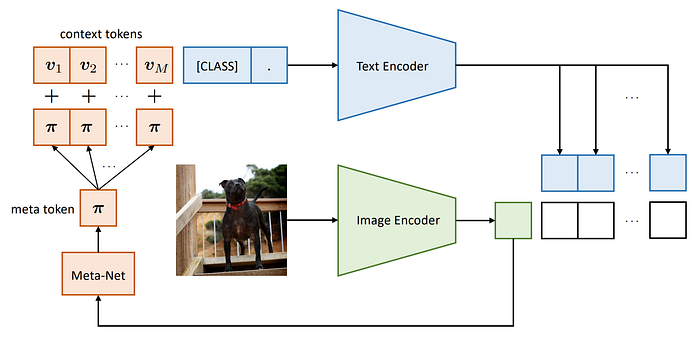
44. VPT
- 論文名稱:Visual Prompt Tuning
- 發布時間:2022/03/23
- 發布單位:康乃爾大學、Facebook(Meta)、哥本哈根大學
- 簡單摘要:把語言模型prompt tuning概念搬到視覺領域
- 閱讀重點:VPT-Shallow、VPT-Deep、Storing Visual Prompts、Ablation on Model Design Variants
- 中文摘要:當前調整預訓練模型的方式通常是更新所有架構參數,也就是全參數微調。所以這篇論文提出了視覺提示微調(VPT),作為大規模Transformer模型在視覺領域中的高效替代方法。受到最近對於有效調整大型語言模型的進展的啟發,VPT在輸入空間中只引入了少量可訓練參數(不到模型參數的1%),同時保持模型架構凍結。通過在多種下游識別任務上進行大量實驗,我們顯示VPT相較於其他參數高效調整協議,實現了顯著的性能提升。最重要的是,在模型容量和訓練數據規模方面,VPT在許多情況下甚至優於全參數微調,同時減少了每個任務的存儲成本。
- 論文連結:https://arxiv.org/pdf/2203.12119.pdf
45. UniCL
- 論文名稱:Unified Contrastive Learning in Image-Text-Label Space
- 發布時間:2022/04/07
- 發布單位:Microsoft
- 簡單摘要:把監督式學習和CLIP自監督學習概念合起來
- 閱讀重點:Unified Image-Text-Label Contrast、Connections to Cross-Entropy、SupCon、CLIP
- 中文摘要:這份論文探討了視覺辨識的學習方式,一種是通過人工標記的圖像標籤數據進行監督學習,另一種是通過網路爬取的圖像文本對進行語言-圖像對比學習。監督學習可能產生更具有辨識性的表徵,而語言-圖像預訓練則展現了前所未有的零樣本識別能力,這主要歸因於不同的數據來源和學習目標。所以該研究提出了一種新的方法,將這兩種數據來源結合到共同的圖像-文本-標籤空間中。在這個空間裡,我們提出了一種新的學習範式,稱為統一對比學習(UniCL),具有單一的學習目標,無縫地促進了這兩種數據類型的協同作用。於大量實驗顯示,UniCL是一種有效的方法,能夠在零樣本、線性探測、完全微調和遷移式學習等場景下,學習具有語義豐富且具辨識性的表徵。特別是在零樣本識別基準上,相對於語言-圖像對比學習和監督學習方法,它分別提高了平均達到9.2%和14.5%的性能。在線性探測設置下,它也比這兩種方法分別提升了7.3%和3.4%的性能。研究還顯示UniCL單獨作為純粹的圖像-標籤數據學習器,能夠與三個圖像分類數據集和兩種視覺架構模型(ResNet和Swin Transformer)的監督學習方法媲美。
- 論文連結:https://arxiv.org/pdf/2204.03610.pdf
46. Flamingo
- 論文名稱:Flamingo: a Visual Language Model for Few-Shot Learning
- 發布時間:2022/04/29
- 發布單位:DeepMind
- 簡單摘要:在訓練好的CV和NLP模型,加個小adapter做in-context
- 閱讀重點:Perceiver Resampler、gated cross-attention dense layers、per-image/video attention masking、in-context learning
- 中文摘要:建立能夠僅使用少量標註範例,迅速適應新任務的模型,是多模態機器學習研究中的一個挑戰。所以我們介紹了Flamingo,一個具有這種能力的視覺語言模型(VLM)家族。我們提出了重要的架構創新,以橋接功能強大的預訓練視覺和語言模型、處理任意交替的視覺和文本數據序列,以及無縫地將圖像或影片作為輸入。由於其靈活性,Flamingo模型可以在包含任意交替文本和圖像的大規模多模態網絡語料庫上進行訓練,這對賦予它們上下文少樣本學習能力至關重要。另外我們對模型進行了全面評估,探索並測量它們快速適應各種圖像和影片任務的能力。這些任務包括開放式任務,如視覺問答,模型需回答提出的問題;標註任務,評估描述場景或事件的能力;以及閉合式任務,如多選視覺問答。對於任何任務,單個Flamingo模型可以透過特定任務的少樣本學習,在眾多基準測試中超越基於數千倍更多特定任務數據微調的模型。
- 論文連結:https://arxiv.org/pdf/2204.14198.pdf
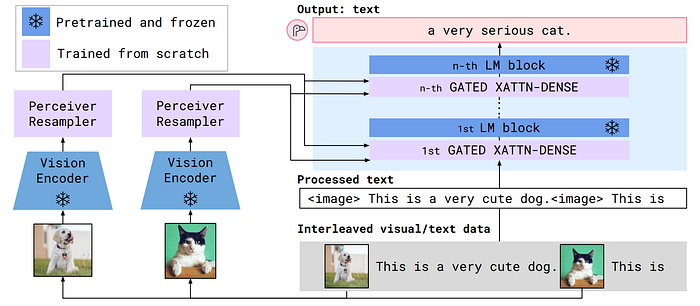
47. CoCa
- 論文名稱:CoCa: Contrastive Captioners are Image-Text Foundation Models
- 發布時間:2022/05/04
- 發布單位:Google
- 簡單摘要:整合Captioning和Contrastive loss,讓下游任務更好做
- 閱讀重點:Single-Encoder Classification、Dual-Encoder Contrastive Learning、Encoder-Decoder Captioning、Contrastive Captioners
- 中文摘要:這篇論文介紹了一種名為「對比式標題生成器」(CoCa)的設計,目標在使用對比損失和標題生成損失聯合預訓練圖像-文字編碼器-解碼器基礎模型,這樣就可以涵蓋對比式方法(如CLIP)和生成式方法(如SimVLM)的模型能力。CoCa與標準的編碼器-解碼器Transformer不同之處在於,它在解碼器的前半部分省略了對編碼器輸出的跨注意力,以編碼單模文字表示,並串聯剩餘的解碼器層,這些層與圖像編碼器進行跨模態圖像-文字表示的交互注意力。除了對多模態解碼器輸出進行生成文本記憶外,我們還應用了單模圖像和文本嵌入之間的對比損失。通過共享相同的計算圖,這兩個訓練目標可以有效地進行計算並具有最小的開銷。另外CoCa在大規模文本數據和帶有標籤的圖像上端到端地進行了預訓練,將所有標籤都簡單地視為文本,無縫地統一了自然語言監督以進行表徵學習。最後實驗結果顯示,CoCa在眾多視覺識別、跨模態檢索、多模態理解和圖像標題生成等下游任務上取得了最先進的性能,無需調整即可進行zero-shot遷移或最小任務特定適應。在ImageNet分類任務中,CoCa獲得了86.3%的zero-shot top-1準確率,凍結編碼器和學習分類頭後達到90.6%,並在ImageNet上以微調編碼器達到了新的91.0% top-1準確率,創下了最新的最高記錄。
- 論文連結:https://arxiv.org/pdf/2205.01917.pdf
48. OWL-ViT
- 論文名稱:Simple Open-Vocabulary Object Detection with Vision Transformers
- 發布時間:2022/05/12
- 發布單位:Google
- 簡單摘要:基於CLIP的想法,創建開放領域目標檢測應用
- 閱讀重點:Open-vocabulary object detection、One- or Few-Shot Transfer、Image-Level Contrastive Pre-Training、Training the Detector
- 中文摘要:透過將簡單的架構與大規模預訓練相結合,我們在圖像分類方面取得了巨大進展。但是在目標檢測方面,預訓練和擴展方法的應用相對較少,尤其是在長尾和開放詞彙的場景下,訓練數據相對較少。所以在這篇論文中,我們提出了一個有效的方法,將圖像-文本模型遷移到開放詞彙的目標檢測中。我們使用了標準的Vision Transformer架構,經過最小程度的修改,進行了對比式圖像-文本預訓練,並進行端到端的檢測微調。我們對這種設置的擴展特性進行了分析,結果顯示增加圖像級別的預訓練和模型尺寸可以持續改善後續的檢測任務。另外我們提供了調整策略和規範化方法,以實現對於零樣本文本條件和單樣本圖像條件的目標檢測具有非常強的性能。
- 論文連結:https://arxiv.org/pdf/2205.06230.pdf

49. GIT
- 論文名稱:GIT: A Generative Image-to-text Transformer for Vision and Language
- 發布時間:2022/05/27
- 發布單位:Microsoft
- 簡單摘要:把image embedding當成prefix丟進語言模型訓練
- 閱讀重點:Network Architecture、text prefix、Pre-training、Fine-tuning、Model and data scaling
- 中文摘要:這篇論文介紹了一種名為Generative Image-to-text Transformer(GIT)的生成式圖像到文本模型,用於統一視覺語言任務,例如圖像/影片標註和問答。雖然生成模型在預訓練和微調之間提供了一致的網絡架構,但是現有工作通常包含複雜的結構(單/多模態編碼器/解碼器),並依賴外部模組,如物體檢測器/標記器和光學字符識別(OCR)。所以在GIT中,我們將架構簡化為單一的圖像編碼器和文本解碼器,在單一的語言建模任務下進行。同時我們擴大了預訓練數據和模型尺寸以提升模型性能。我們的GIT在12個具有挑戰性的基準測試中創下了新的最佳表現,例如在TextCaps(CIDEr得分:138.2 vs. 125.5)上,我們的模型首次超越了人類表現。此外我們提出了一種新的基於生成的圖像分類和場景文本識別方案,在標準基準測試上取得了不錯的表現。
- 論文連結:https://arxiv.org/pdf/2205.14100.pdf
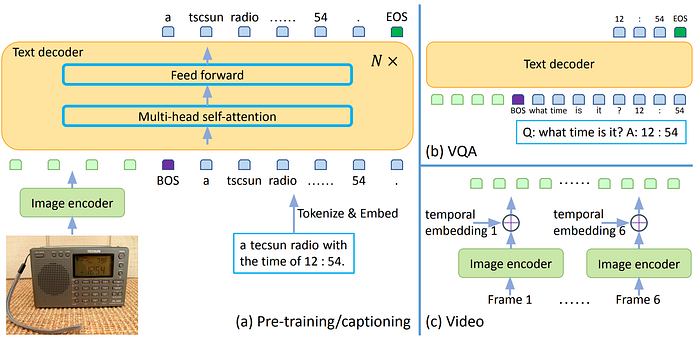
50. BEiT v3
- 論文名稱:Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
- 發布時間:2022/08/22
- 發布單位:Microsoft
- 簡單摘要:基於Multiway Transformer,使用MMoE架構劃分不同expert
- 閱讀重點:Multiway Transformers、Masked Data Modeling、Scaling Up、Vision-Language Downstream Tasks
- 中文摘要:在語言、視覺和多模態預訓練領域出現了重大的整合。所以我們引入了一個通用的多模態基礎模型 BEiT-3,它在視覺和視覺語言任務上實現了最先進的遷移性能力。具體來說,我們從三個方面推進了這種大整合:模型架構、預訓練任務和模型擴展。這邊我們引入了多路Transformer以進行通用建模,模塊化的架構使得深度融合和特定模態編碼都成為可能的事情。而基於共享的骨幹架構,我們以統一的方式對圖像(Imglish)、文本(English)和圖像-文本對(”平行句子”)進行了遮罩”語言”建模。實驗結果顯示,BEiT-3在目標檢測(COCO)、語義分割(ADE20K)、圖像分類(ImageNet)、視覺推理(NLVR2)、視覺問答(VQAv2)、圖像標註(COCO)和跨模態檢索(Flickr30K、COCO)等任務上取得了最先進的性能。
- 論文連結:https://arxiv.org/pdf/2208.10442.pdf
51. PaLI
- 論文名稱:PaLI: A Jointly-Scaled Multilingual Language-Image Model
- 發布時間:2022/09/14
- 發布單位:Google
- 簡單摘要:Transformer+ViT,架構簡單、效果好、又容易拓展
- 閱讀重點:architecture、ViT-e、The language component、The overall model、Training mixture
- 中文摘要:我們提出了PaLI(Pathways Language and Image model),這是一個將語言和視覺聯合建模的模型。PaLI根據視覺和文本輸入生成文本,並利用這種介面執行許多視覺、語言和多模態任務,並支援多種語言。為了訓練PaLI,我們利用了大型預訓練的編碼器-解碼器語言模型和Vision Transformers(ViTs)。這讓我們能夠充分利用它們現有的功能,並善用它們訓練的巨大成本。另外我們發現視覺和語言組件的聯合擴展至關重要,而由於現有的語言Transformer比視覺對應組件更大,我們訓練了一個擁有40億參數的大型ViT(ViT-e),以量化更大容量的視覺模型帶來的好處。為了訓練PaLI,我們創建了一個大型多語種的預訓練任務組合,基於包含超過100種語言的新圖像文本訓練集,其中包含100億張圖像和文本。PaLI在多個視覺和語言任務上達到了最先進水平(例如標註、視覺問答、場景文本理解),同時保持了簡單、模塊化和可擴展的設計。
- 論文連結:https://arxiv.org/pdf/2209.06794.pdf
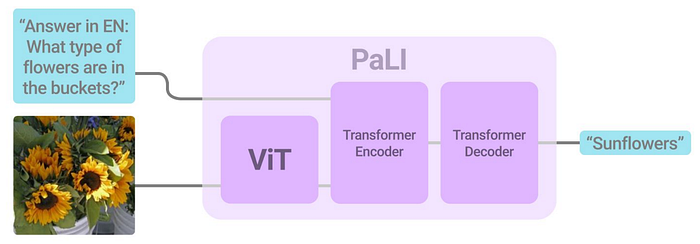
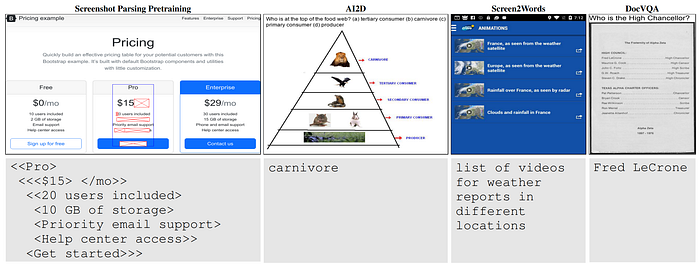
52. Pix2Struct
- 論文名稱:Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
- 發布時間:2022/10/07
- 發布單位:Google、succinctly.ai、劍橋大學
- 簡單摘要:輸入網頁頁面截圖,輸出html的結構性輸出
- 閱讀重點:Architecture、Screenshot parsing inputs & outputs、reading curriculum
- 中文摘要:視覺和語言的結合無處不在,來源包括圖解的教科書、含有圖像和表格的網頁,以及擁有按鈕和表單的手機應用程式。可能因為這樣的多樣性,以往的研究通常依賴特定領域的方法,並且在底層數據、模型結構和目標方面缺乏共享。所以我們提出了Pix2Struct,這是一個預訓練的圖像到文本模型,專注於純粹的視覺語言理解,可進行包含視覺和語言結合的任務微調。Pix2Struct的預訓練是通過學習將網頁的屏幕截圖解析成簡化的HTML來完成的。網頁中豐富的視覺元素清晰地反映在HTML結構中,為下游任務提供了豐富的預訓練數據。直觀地說,這個目標涵蓋了常見的預訓練訊號,比如OCR、語言建模和圖像標註。除了新穎的預訓練策略,我們還引入了可變解析度的輸入表徵和更靈活的語言和視覺輸入整合,其中語言提示,比如問題,直接顯示在輸入圖像上方。最後我們首次展示了一個單一預訓練模型,在四個領域的九個任務中,有六個任務達到了最先進的結果:文件、插圖、用戶界面和自然圖像。
- 論文連結:https://arxiv.org/pdf/2210.03347.pdf
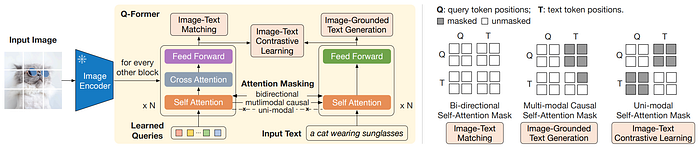
53. BLIP-2
- 論文名稱:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 發布時間:2023/01/30
- 發布單位:Salesforce
- 簡單摘要:兩階段分別Boostrap,參數凍結的image encoder和LLM
- 閱讀重點:Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder、Generative Learning from a Frozen LLM
- 中文摘要:這篇論文提出了BLIP-2,一種通用且高效的預訓練策略,它能從現成的凍結圖像編碼器和大型語言模型出發,啟動視覺語言的預訓練。BLIP-2利用輕量級的查詢Transformer來彌補模態差異,其分為兩個階段進行預訓練。第一階段從凍結的圖像編碼器開始視覺語言表徵學習,第二階段則從凍結的語言模型開始視覺到語言的生成式學習。雖然可訓練參數顯著少於現有方法,但BLIP-2在各種視覺語言任務上實現了最先進的性能。例如在零樣本VQAv2任務中,我們的模型比Flamingo80B的性能高出了8.7%,而可訓練參數少了54倍。我們還展示了模型的新能力,即零樣本圖像到文本生成,能夠按照自然語言指示進行生成。
- 論文連結:https://arxiv.org/pdf/2301.12597.pdf
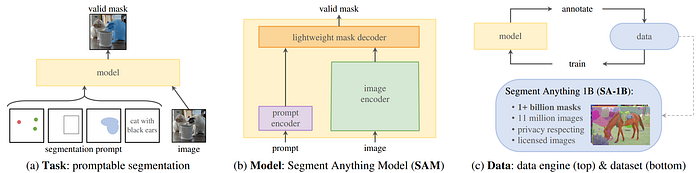
54. SAM
- 論文名稱:Segment Anything
- 發布時間:2023/04/05
- 發布單位:Facebook(Meta)
- 簡單摘要:可以prompt的分割模型,和一個超巨大的分割資料集
- 閱讀重點:Image encoder、Prompt encoder、Mask decoder、Resolving ambiguity、Data Engine、Dataset
- 中文摘要:我們推出了「Segment Anything(SA)」計畫:這是一個新的影像分割任務、模型和數據集。我們利用高效的模型在資料收集循環中建立了迄今為止最大的分割數據集,包含超過1100萬張受授權且尊重隱私的影像,擁有超過10億個遮罩(mask)。這個模型設計和訓練成可提示式,因此能夠在零樣本情況下適應新的影像分佈和任務。另外我們對其在眾多任務上進行評估,發現它的零樣本表現令人印象深刻,往往與或甚至優於先前完全監督的結果相競爭。最後我們將釋出「Segment Anything Model(SAM)」和相應的數據集(SA-1B),包含10億個遮罩和1100萬張影像,以促進計算機視覺基礎模型的研究。
- 論文連結:https://arxiv.org/pdf/2304.02643.pdf
55. SEEM
- 論文名稱:Segment Everything Everywhere All at Once
- 發布時間:2023/04/13
- 發布單位:威斯康辛大學麥迪遜分校、Microsoft、香港科技大學
- 簡單摘要:Visual Prompt、Text Prompt、Ref Prompt通通都可分割
- 閱讀重點:Model Design、Versatile、Compositional、Interactive、Semantic-aware、Model Pipeline and Loss Functions
- 中文摘要:這份研究提出了SEEM,這是一個可提示和互動的模型,能夠在一張圖像中同時進行全域的所有區段分割。在SEEM中,我們提出了一種新的解碼機制,能夠針對各種分割任務進行多樣的提示,旨在打造一個像大型語言模型(LLMs)般通用的分割介面。具體而言,SEEM設計了四個主要特點:i)多功能性。我們引入了一種新的視覺提示方式,統一了不同空間查詢,包括點、方框、塗鴉和遮罩,進一步能夠應用於不同的參考圖像;ii)組成性。我們學習了文字和視覺提示之間的聯合視覺-語義空間,便於動態組合各種分割任務所需的兩種提示類型;iii)互動性。我們在解碼器中進一步融入可學習的記憶提示,通過從解碼器到圖像特徵的遮罩引導交叉注意力,保留分割歷史記錄;iv)語義感知性。我們使用文本編碼器將文本查詢和遮罩標籤編碼到相同的語義空間中,以進行開放詞彙的分割。另外我們進行了全面的實驗研究,驗證了SEEM在多種分割任務中的有效性。值得注意的是,我們的單個SEEM模型在9個數據集上,即使只有1/100的監督,也能在互動分割、通用分割、參考分割和視頻物體分割方面取得競爭性的性能。最後SEEM展示了對新提示或其組合的出色泛化能力,使其成為一個通用的圖像分割界面。
- 論文連結:https://arxiv.org/pdf/2304.06718.pdf
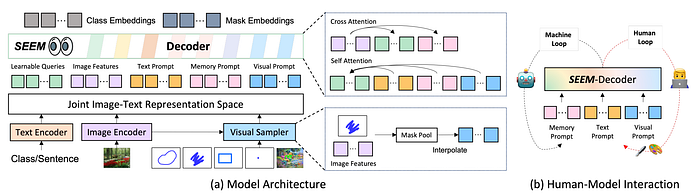
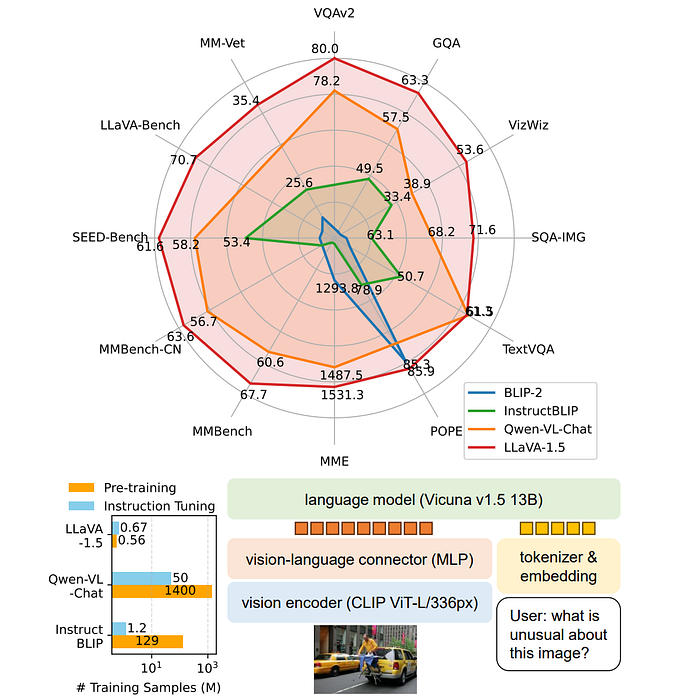
56. LLaVA
- 論文名稱:Visual Instruction Tuning
- 發布時間:2023/04/17
- 發布單位:威斯康辛大學麥迪遜分校、Microsoft、哥倫比亞大學
- 簡單摘要:基於LLaMA且目前最普遍使用的開源VLM模型
- 閱讀重點:GPT-assisted Visual Instruction Data Generation、Visual Instruction Tuning、LLaVA-Bench、Limitations
- 中文摘要:透過使用語言導向的 GPT-4 生成多模態語言-圖像指示數據,我們開創了在多模態領域中利用指令調整大型語言模型(LLMs)的嶄新嘗試。我們引入了 LLaVA(Large Language and Vision Assistant),這是一個端對端訓練的大型多模態模型,將視覺編碼器和LLM連接起來,用於通用的視覺和語言理解。初步實驗顯示,LLaVA展現了令人印象深刻的多模對話能力,有時展示了對未見過圖像/指示的多模態GPT-4的行為,相對於合成的多模式指示遵循數據,相對得分達到了85.1%。當在科學問答上進行精細調整時,LLaVA和GPT-4的協同作用實現了新的92.53%的最高準確率。
- 論文連結:https://arxiv.org/pdf/2304.08485.pdf
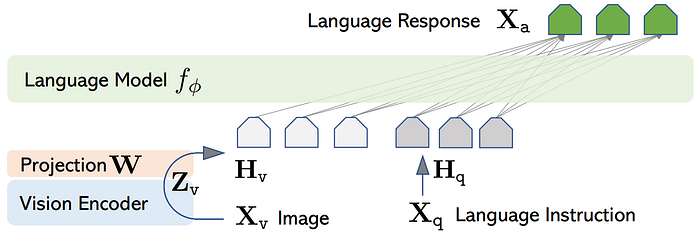
57. MiniGPT
- 論文名稱:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
- 發布時間:2023/04/20
- 發布單位:阿布都拉國王科技大學
- 簡單摘要:輸入影像的ViT和文字的Vicuna鎖住,只tune中間的MLP
- 閱讀重點:first pretraining stage、Initial aligned image-text generation、Data post-processing
- 中文摘要:近期的GPT-4展示了非凡的多模態能力,例如直接從手寫文字生成網站,並識別圖像中的幽默元素。這些功能在以前的視覺語言模型中很少見,但是GPT-4背後的技術細節仍然未公開。所以我們相信GPT-4增強的多模態生成能力源於先進的大型語言模型(LLM)的應用。為了探討這一現象,我們提出了MiniGPT-4,它將一個凍結的視覺編碼器與一個凍結的先進LLM(Vicuna)對齊,並使用一個投影層。我們的研究首次揭示了,將視覺特徵與先進的大型語言模型正確對齊,可以擁有GPT-4展示的許多先進的多模態能力,例如生成詳細的圖像描述以及從手繪草稿創建網站。此外我們還觀察到MiniGPT-4的其他新能力,包括根據給定的圖像寫故事和詩歌,以圖片教用戶如何烹飪等。在我們的實驗中,我們發現只訓練短圖像標題對會導致不自然的語言輸出(例如,重複和碎片化)。為了解決這個問題,我們在第二階段精心整理了一個詳細的圖像描述數據集,用於微調模型,從而提高了模型的生成可靠性和整體可用性。
- 論文連結:https://arxiv.org/pdf/2304.10592.pdf

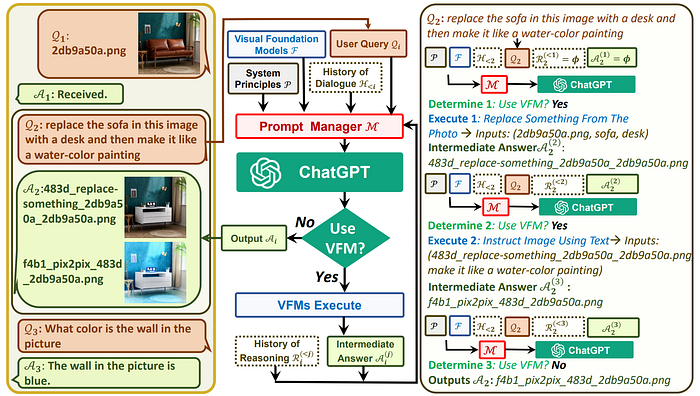
58. Visual ChatGPT
- 論文名稱:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
- 發布時間:2023/05/08
- 發布單位:Microsoft
- 簡單摘要:ChatGPT雖然不會看圖片,但加一個視覺模型prompt就可以
- 閱讀重點:Prompt Managing of System Principles、Foundation Models、User Querie、Foundation Model Outputs
- 中文摘要:ChatGPT因其在多個領域展現出卓越的對話能力和推理能力,吸引了跨領域的興趣。但是由於ChatGPT僅訓練於語言,目前無法處理或生成來自視覺世界的圖像。與此同時,像視覺Transformer或Stable Diffusion等視覺基礎模型雖然展示出出色的視覺理解和生成能力,但它們只專精於特定任務,且僅能接受單一輸入並給出固定輸出。因此我們建立了一個名為「Visual ChatGPT」的系統,結合不同的視覺基礎模型,使用戶能夠:1) 發送和接收語言和圖像;2) 提供複雜的視覺問題或需要多步驟多AI模型協作的視覺編輯指令;3) 提供反饋並請求修正結果。我們設計了一系列提示,將視覺模型的訊息注入ChatGPT,考慮到多輸入/輸出模型和需要視覺反饋的模型。實驗顯示,視覺ChatGPT為探索ChatGPT在視覺角色方面打開了新的可能性,並與視覺基礎模型進行了有效整合。
- 論文連結:https://arxiv.org/pdf/2303.04671.pdf
59. InstructBLIP
- 論文名稱:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- 發布時間:2023/05/11
- 發布單位:Salesforce、香港科技大學、南洋理工大學
- 簡單摘要:在BLIP上面加上instruction tuning
- 閱讀重點:Training and Evaluation Protocols、Instruction-aware Visual Feature Extraction、Balancing、Inference、Architecture
- 中文摘要:大規模預訓練和指令調整已成功創建了具有廣泛能力的通用語言模型。然而建立通用的視覺與語言模型時,因具有豐富的輸入分佈和任務多樣性而具有挑戰性,這源於額外的視覺輸入。儘管視覺與語言的預訓練已被廣泛研究,但視覺與語言的指令調整仍未得到充分探索。所以本文基於預訓練的BLIP-2模型,對視覺與語言的指令調整,進行了系統和全面的研究。我們收集了26個公開數據集,涵蓋各種任務和能力,並將它們轉化為指令調整格式。此外我們引入了一個指令感知的Query Transformer,其可提取適合給定指令的訊息特徵。在13個保留的數據集上訓練後,InstructBLIP 在所有13個保留的數據集上取得了zero-shot的最新表現,在性能上大幅優於BLIP-2和更大的Flamingo模型。我們的模型在進行單獨下游任務的微調時也達到了最新的性能(例如,在具有圖像內容的ScienceQA問題上達到了90.7%的準確率)。此外我們也展示了InstructBLIP相對於同時存在的多模態模型的優勢。
- 論文連結:https://arxiv.org/pdf/2305.06500.pdf

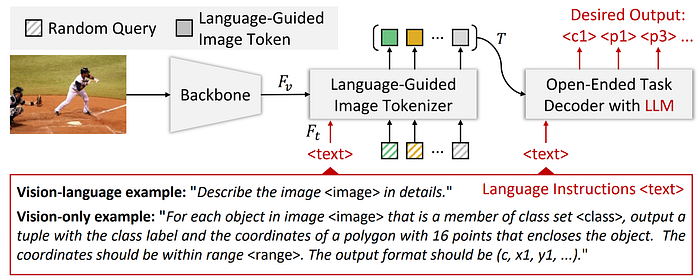
60. VisionLLM
- 論文名稱:VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
- 發布時間:2023/05/18
- 發布單位:Shanghai AI Lab、北京大學、南京大學、北京清華大學
- 簡單摘要:以LLM為中心,引入image tokenizer來解決各種不同的任務
- 閱讀重點:Architecture、Unified Language Instruction、Language-Guided Image Tokenizer、Open-Ended Task Decoder
- 中文摘要:大型語言模型(LLMs)顯著加速了通用人工智慧(AGI)的進展,其令人印象深刻的zero-shot能力,使它們在各種應用中具有巨大潛力,可以為用戶量身定制的任務提供支持。但是在電腦視覺領域中,儘管有許多強大的視覺基礎模型(VFMs),它們仍然局限於預定義形式的任務,難以與LLMs的開放任務能力相匹配。所以在這項工作中,我們提出了一個基於LLM的視覺中心任務框架,稱為VisionLLM。該框架將圖像視為一種外語,通過將以視覺為中心的任務與可以使用語言指令進行靈活定義和管理的語言任務對齊,提供了視覺和語言任務的統一視角。接著基於這些指令,LLM-based解碼器可以針對開放性任務進行適當的預測。最後大量實驗顯示,我們所提出的VisionLLM可以通過語言指令在不同細緻度的任務定制方面取得良好結果,從細粒度的物體級別到粗粒度的任務級別。值得注意的是,通過通用LLM框架,我們的模型可以在COCO上實現超過60%的mAP,與特定於檢測的模型相當。我們希望這個模型能為通用的視覺和語言模型設立新的基準。
- 論文連結:https://arxiv.org/pdf/2305.11175.pdf
61. Improved LLaVA
- 論文名稱:Improved Baselines with Visual Instruction Tuning
- 發布時間:2023/10/05
- 發布單位:威斯康辛大學麥迪遜分校、Microsoft
- 簡單摘要:LLaVA的改良版,用了更大的CLIP和更多的數據
- 閱讀重點:Response formatting prompts、MLP vision-language connector、Academic task oriented data、Additional scaling
- 中文摘要:最近大型多模態模型(LMM)在視覺指令調整方面展示了令人鼓舞的進展。所以在這篇論文中,我們展示了LLaVA中完全連接的視覺語言跨模態連接器,能達到出人意料的強大和高效率。通過對LLaVA進行簡單修改,即使用CLIP-ViT-L-336px搭配MLP投影,以及添加以學術任務為導向的VQA數據和簡單的回答格式提示,讓我們建立了更強的基準線,並在11個基準測試中取得了最先進的成果。最終我們的13B檢查點僅使用了120萬筆公開數據,在單個8-A100節點上的完整訓練僅需約1天時間。希望這能讓最先進的LMM研究更容易接觸。
- 論文連結:https://arxiv.org/pdf/2310.03744.pdf
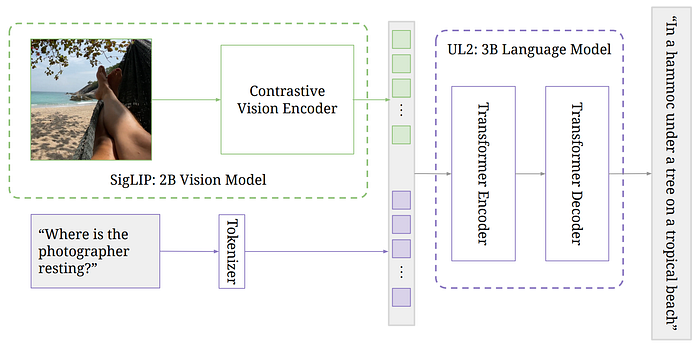
62. PaLI-3
- 論文名稱:PaLI-3 Vision Language Models: Smaller, Faster, Stronger
- 發布時間:2023/10/13
- 發布單位:Google、DeepMind
- 簡單摘要:把CLIP換成SigLIP用在PaLI上,表現得更好
- 閱讀重點:Visual component、Full PaLI model、Unimodal pretraining、Multimodal training、Resolution increase
- 中文摘要:這篇論文介紹了 PaLI-3,一種更小、更快、更強大的視覺語言模型(VLM),與大小為其 10 倍的相似模型相比表現良好。為達到強大的表現,我們比較了使用分類目標預訓練的 Vision Transformer(ViT)模型和對比式(SigLIP)預訓練模型。我們發現雖然 SigLIP 的 PaLI 在標準圖像分類基準測試中表現稍微不如,但在各種多模態基準測試中,特別是在定位和視覺文本理解方面表現優越。另外我們也將 SigLIP 圖像編碼器擴展到 20 億個參數,並在多語言跨模態檢索上達到了新的最先進水準。我們希望只有 50 億參數的 PaLI-3 能重新引發對複雜 VLM 基本組成部分的研究,並推動新一代的擴展模型的發展。
- 論文連結:https://arxiv.org/pdf/2310.09199.pdf
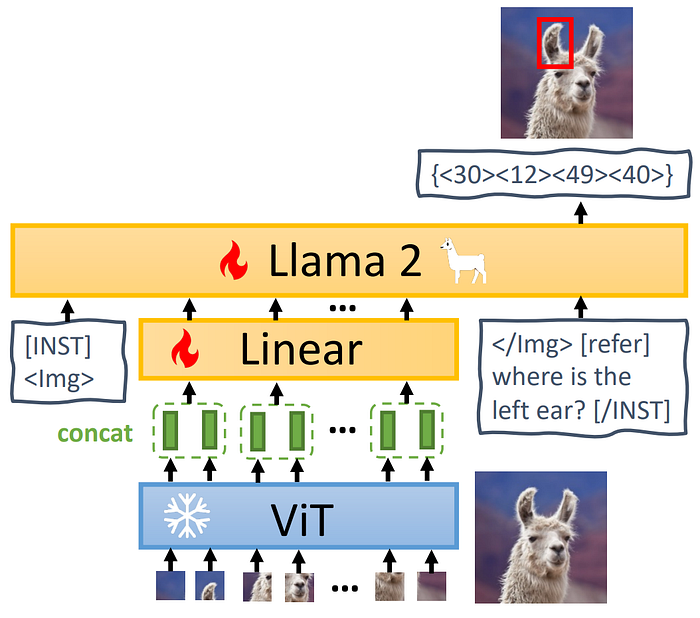
63. MiniGPT v2
- 論文名稱:MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
- 發布時間:2023/10/14
- 發布單位:阿布都拉國王科技大學、Facebook(Meta)
- 簡單摘要:MiniGPT改良版,基礎架構換成LLaMA 2
- 閱讀重點:Visual backbone、Linear projection layer、Large language model、Multi-task Instruction Template & Training
- 中文摘要:大型語言模型展現了在各種語言相關應用中的非凡能力。受此啟發,我們致力於建立一個統一介面,能夠應對多種視覺與語言任務,包括圖像描述、視覺問答和視覺定位等。挑戰在於使用單一模型有效地執行各種視覺與語言任務,並使用簡單的多模式指令。為了達到這個目標,我們推出了MiniGPT-v2,這是一個能更好地處理各種視覺與語言任務的統一介面模型。我們提出在訓練模型時為不同任務使用獨特的識別符號。這些識別符號能讓我們的模型輕鬆地更好地辨識每個任務指令,同時提高了模型對每個任務的學習效率。在經過三階段訓練後,實驗結果顯示,與其他視覺與語言通用模型相比,MiniGPT-v2在許多視覺問答和視覺定位基準測試中表現出了強大的性能。
- 論文連結:https://arxiv.org/pdf/2310.09478.pdf
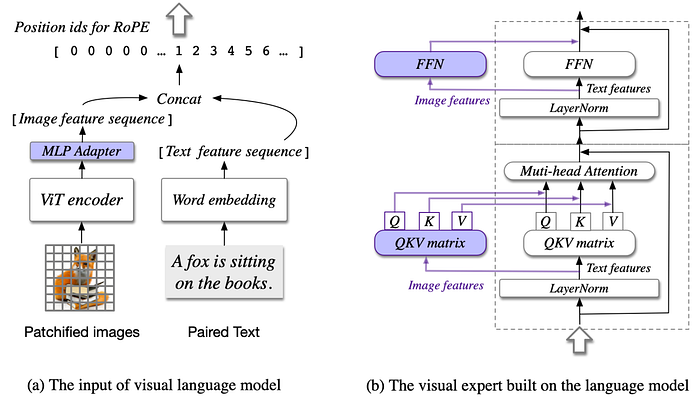
64. CogVLM
- 論文名稱:CogVLM: Visual Expert for Pretrained Language Models
- 發布時間:2023/11/06
- 發布單位:北京清華大學、Zhipu AI
- 簡單摘要:在Transformer裡面多加一個針對視覺的QKV矩陣expert
- 閱讀重點:ViT encoder、MLP adapter、Pretrained large language model、Visual expert module
- 中文摘要:我們推出了CogVLM,一個強大的開源視覺語言基礎模型。不同於流行的淺層對齊方法,將圖像特徵映射到語言模型的輸入空間,CogVLM通過在注意力和FFN層中使用可訓練的視覺專家模組,將凍結的預訓練語言模型和圖像編碼器之間的差距。因此CogVLM能夠深度融合視覺語言特徵,而不會在自然語言處理任務上犧牲性能。CogVLM-17B在10個經典跨模態基準測試中取得了最先進的性能,包括NoCaps、Flicker30k圖片標註、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA和TDIUC,並在VQAv2、OKVQA、TextVQA、COCO圖片標註等方面排名第二,超越或與PaLI-X 55B相媲美。
- 論文連結:https://arxiv.org/pdf/2311.03079.pdf
65. VCD
- 論文名稱:Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
- 發布時間:2023/11/28
- 發布單位:阿里巴巴、南洋理工大學
- 簡單摘要:在視覺輸入加入雜訊,讓VLM做自監督學習
- 閱讀重點:Decoding of Vision-Language Models、Visual Uncertainty Amplifies Hallucinations、Visual Contrastive Decoding
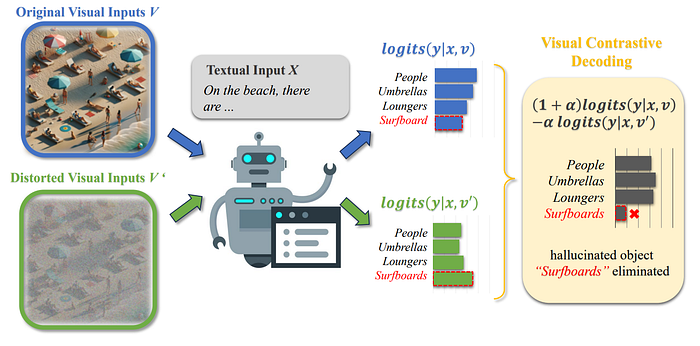
- 中文摘要:大型視覺語言模型(LVLMs)已經有了顯著進展,將視覺辨識和語言理解緊密結合,生成的內容不僅連貫,而且與上下文相關。儘管取得成功,但LVLMs仍然存在物件幻覺的問題,模型會生成看似合理但錯誤的輸出,其中包含圖像中不存在的物件。為了緩解這個問題,我們引入了視覺對比解碼(VCD),這是一種簡單且無需額外訓練的方法,它對比了從原始和扭曲的視覺輸入中獲得的輸出分佈。所提出的VCD有效地減少了對統計偏差和單模態先驗的過度依賴,這兩者是導致對象幻覺的兩個重要原因。這種調整確保了生成的內容與視覺輸入密切相關,產生了上下文準確的輸出。我們的實驗顯示,VCD在不需要額外訓練或使用外部工具的情況下,顯著減輕了不同LVLM系列中的物件幻覺問題。除了緩解物件幻覺問題外,VCD在一般的LVLM基準測試中也表現出色,突顯了其廣泛的應用性。
- 論文連結:https://arxiv.org/pdf/2311.16922.pdf
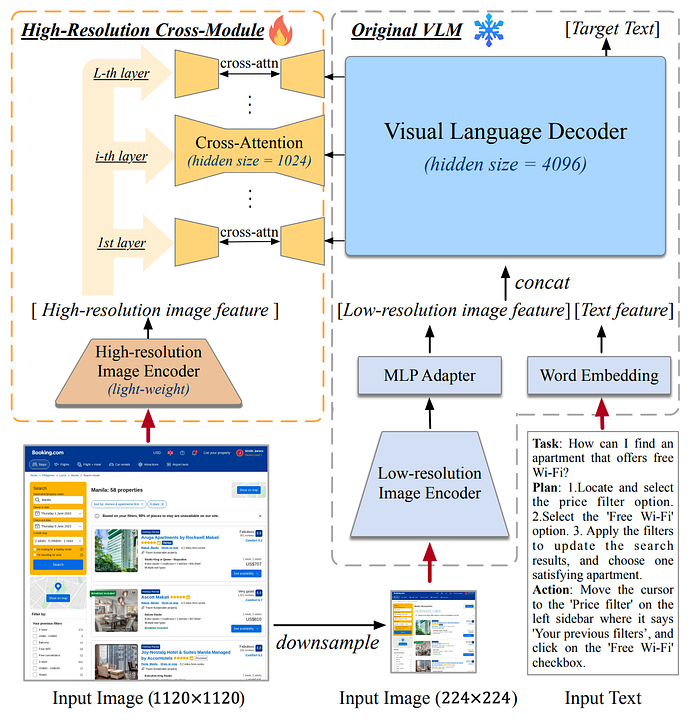
66. CogAgent
- 論文名稱:CogAgent: A Visual Language Model for GUI Agents
- 發布時間:2023/12/14
- 發布單位:北京清華大學、Zhipu AI
- 簡單摘要:把CogVLM當作agent,來瀏覽網路和手機螢幕
- 閱讀重點:Architecture、High-Resolution Cross-Module、Pre-training、Multi-task Fine-tuning and Alignment
- 中文摘要:人們在數位設備上花費了大量時間,透過圖形使用者介面(GUI),例如電腦或智慧型手機螢幕。大型語言模型(LLMs)如ChatGPT可以協助人們撰寫電子郵件等任務,但在理解和與GUI互動方面存在困難,因此限制了它們提高自動化水平的潛力。所以在這篇論文中,我們介紹了CogAgent,這是一個180億參數的視覺語言模型(VLM),專門用於理解和導航GUI。CogAgent利用低解析度和高解析度圖像編碼器,支持1120 x 1120的輸入解析度,能夠識別微小的頁面元素和文字。作為一個通用的視覺語言模型,CogAgent在五個文本豐富和四個一般VQA基準測試中達到了最先進的水準,包括VQAv2、OK-VQA、Text-VQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet和POPE。CogAgent僅使用螢幕截圖作為輸入,在PC和Android的GUI導航任務中,表現優於使用提取的HTML文本的基於LLM的方法 — — Mind2Web和AITW,推動了技術的最新進展。
- 論文連結:https://arxiv.org/pdf/2312.08914.pdf
小補充
最後對於想要更全面了解VLM的朋友們,我非常推薦你們去看Mu Li這個頻道,他在裡面有去精讀VLM模型的重要論文,總計大概兩個多小時,影片是中文的,講得非常好,可以無痛服用。
另外我們可以看到其實VLM是基於很多大型視覺模型和大型語言模型去作為基礎的,所以這邊有興趣的朋友也推薦你們去補一下LLM的論文,以及ViT、Swin Transformer、BEiT、Masked Autoencoder後面的原理。最後祝大家學習和工作順利啦!
作者:劉智皓
