榨乾GPU效能的Flash Attention 3
Hello大家好久不見,因為最近工作實在太忙了,好一陣子沒有更新Medium,今天心血來潮來寫一篇。
前言
相信江湖中的AI Engineer和AI Researcher一定都聽過,Flash Attention這個突破性的演算法,而就在這幾個月終於推出了Flash Attention V3,號稱TFLOPS又比Flash Attention V2高1.5~2倍
BUT!!!
遺憾的是
FlashAttention V3目前只有支援Nvidia Hopper架構的GPU
@@,所以真的是窮人玩不起AI阿。OK所以今天我們就要來講FlashAttention V3這個演算法,而在講這個演算法之前,我會先介紹FlashAttention V1和V2,如果已經知道這兩個演算法的朋友可以直接跳到V3!
Standard Attention
在Transformer架構當中,Attention是整個模型中最重要的運算,而這個Attention的運算演算法如下:


首先我們把query state和key state做矩陣相乘,接下來就是除以Transformer head dimension數量的開根號,然後我們會把運算出來的結果S (Score)丟進入Softmax函數得到P,最後P再和value state做矩陣相乘就會得到Attention的輸出O。
但實際上我們會發現這一連串的運算非常的耗時間,且會使用到非常大量的記憶體。首先我們的GPU架構中,可以把記憶體簡單地分成HBM(High Bandwidth Memory)和SRAM(Static Random Access Memory)兩個部分
HBM的記憶體空間雖然很大,但是他的頻寬比較低
SRAM的記憶體空間雖然很小,但是他的頻寬非常高
所以我們常常看GPU寫的,像是Nvidia RTX 4090 24 GB,就是這張GPU有大約24GB大小的HBM。而SRAM這塊又貴又小的記憶體,就是拿來做運算的。

所以我們可以看到今天你在你的GPU跑Attention他的流程如下 (N: sequence length、d是head dimension)

首先我們會把query state和key state從HBM拉到SRAM運算,接下來把算出來的結果S寫回去HBM,然後GPU又把S拉到SRAM計算softmax,算出來P又寫回HBM,最後P和value state從HBM寫到SRAM做矩陣運算,最後輸出O寫回HBM。
而實際情況當然沒那麼簡單,我們知道SRAM這塊記憶體又貴又小,所以當然不可能直接把整個query state或是key state load進去SRAM,其是一小塊一小塊的Load。所以這樣大量的讀寫導致Attention運算速度很慢,而且會有記憶體碎片化問題。
FlashAttention V1
第一招:Kernel Fusion
相信聰明的朋友,看到馬上就會知道,阿幹嘛這樣load上load下的,一次在SRAM乖乖把所有東西算完不就好了?沒錯這就是FlashAttention的精隨之一。
FlashAttention就是直接把QKV一次load到SRAM計算完所有東西,再把O寫回HBM
這樣就可以大大減少讀寫次數,而在這種一次把所有運算一次算完的流程叫做Kernel Fusion。
第二招:Backward Recomputation
但是等等,我們是不是忘了什麼?我們把O直接算出來,P跟S難道就直接丟掉不存回HBM嗎?那麼我們今天做backward propagation的時候,我們要把梯度從O推回P,P再推回S,他們都被我們丟掉了要怎麼backward?沒錯這就是FlashAttention的第二招,Backward Recomputation。
因為P和S這兩位實在太佔據空間了,所以我們
Foward的時候P和S都不會存起來,當我們在Backward的時候,我們就會再計算一次Forward把P和S再算出來,讓我們可以執行Backward,所以說
我們執行了2次Forward 1次Backward。
這裡大家可能又會問:阿這樣計算不就多了更多計算量怎麼可能比較快?事實上雖然我們重新計算了一次forward,但是他不但幫我們省下了存P和S的記憶體空間,也省下P和S再HBM和SRAM之間搬運的時間,讓我們可開更大的batch size,所以整體來說GPU每秒能算的資料量,依然是大幅增加。
第三招:Softmax Tiling
最後是FlashAttention的最後一招Tiling,首先我們要先知道Attention當中的大魔王就是Softmax Function:
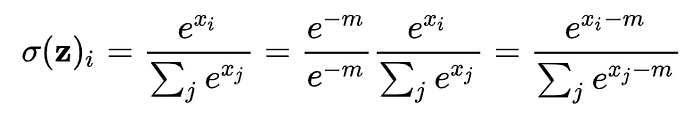
主要原因就是算分母的時候,我們要把所有欄位的exp值加總外,我們還會需要知道m,就是x裡面的最大值,但是受限於SRAM的大小關係,我們不可能一次算出所有數值的softmax,一定是要一塊一塊的丟進SRAM計算,所以需要把所有中間計算的數值存在HBM。
而tiling的做法就是,我們先把一塊丟進去計算出softmax,而這裡的m代表的是這一塊load到SRAM的最大值,所以我們稱為local maxima,而後面我們就可以根據m計算出local softmax
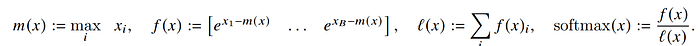
接下來第二塊進來我們把第一塊的最大值和第二塊的最大值取最大值,就可以得到這兩塊數值的最大值,這個時候因為exp(-m)是相乘的關係,所以我們只要需要把第一塊的local softmax乘上這次更新的數值,具體來說第一塊f(x)=exp(-m1),所以第二塊加進來的時候我們會乘上exp(m1-m),這裡的m就是兩塊數值的local maxima,同理我們也用相通方式推算,如此一來我們就得到這兩塊的local softmax。
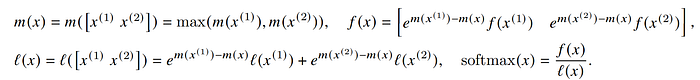
沒錯!接下來依此類推,我們就可以把整個softmax算完,而透過這個方式,
我們就不需要把每塊算出來的數值存在HBM,我們只需要存當下的最大值m(x)和分母加總l(x)就可以了
而這兩個東西都很小,所以可以再幫我們省下更多記憶體空間。
另外這邊還有一個小細節就是因為softmax算出來要跟value state做矩陣相乘,但是一樣SRAM有限,我們一次只能load一塊做kernel fusion運算,所以第一塊QKV進去,他算出來的O是不準確的,但因為矩陣相乘,就是數字相乘,所以同樣道理,我們只要計算到下一塊時,使用l和m更新O就可以了。
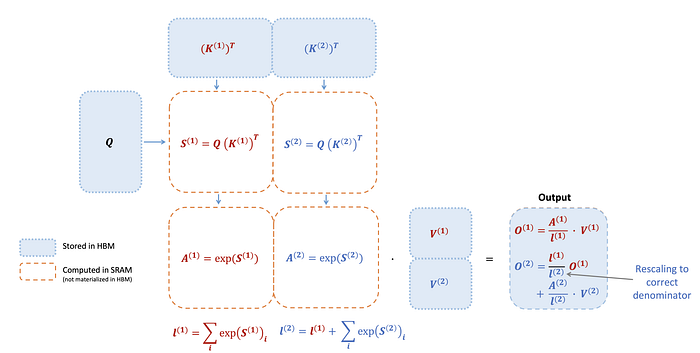
我們可以看到實際上的流程就會是這樣,藍色的區塊就是HBM,橘色虛線的區塊就是SRAM,每次運算的時候,因為SRAM大小有限,所以我們只Load一部分的Key state和value state,紅色的字就是我們第一個block的計算,藍色的字就是我們第二個block的計算。
這邊我們可以更加深入到演算法和實作的部分,老話一句SRAM很小,今天sequence length很長的時候,根本不可能把這麼巨大的query、key、value state一次全部塞到SRAM。
從下面forward和backward的演算法可以看到,基本上一開始的時候我們會把Query State切成T_r塊,Key/Value State切成T_c塊,而Query State block的大小是(B_r,d),Key/Value State的大小是(B_c,d),切好的這些block再丟到SRAM上做Flash Attention的運算。
你可能會很疑惑B_r和B_c是什麼magic number,其實超級簡單,M是我們SRAM的大小,然後QKVO四個矩陣的大小一模一樣,所以當然是M/4d啦,這樣QKVO四個矩陣的block加在一起不就剛好是M嘛,也就是說剛好塞滿SRAM。
Forward演算法

Backward演算法

最後我們來看一下他的performance:
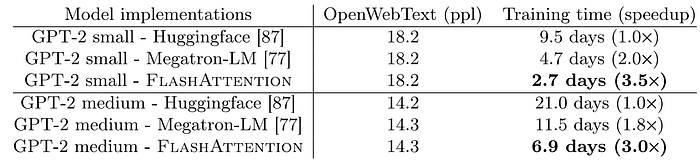
我們可以看到FlashAttention大大的加速的運算達到3倍以上。
FlashAttention V2
OK那看到這邊我們大概了解了FlashAttention的原理,那接下來就是FlashAttention V2。
Forward優化
我們在前面的時候了解,因為是一塊一塊load進SRAM,所以每一回計算新的O都需要更新:
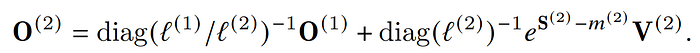
我們可以看到O每次都會做rescale就是乘上diag(l)^-1,但其實我們不需要每次都去做這個運算,我們其實只要做unscale就可以了
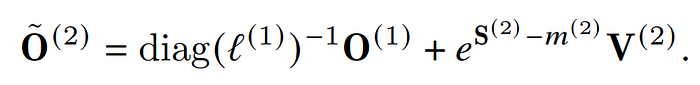
因為每次都只是相乘,我們只需每次算完一塊把這一回的l更新且保存起來就好,最後在把最後一輪更新的l,去rescale O就可以了
如此一來就可以省下一些計算時間。
Backward優化
另外一個可以優化的地方就是在FlashAttention V1 Forward做完後,我們m和l都會存起來以讓Backward可以計算,這邊我們可以回顧Flash Attention V1 Backward演算法的這一行:
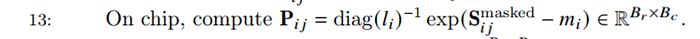
l和m只會在這裡用到,所以我們在FlashAttention V2中
因為我們已經知道backward回推的公式,我們只需要把logsumexp L

存起來就好,這樣又可以減少一些記憶體使用量
Casual Mask優化
另外一個優化的的地方就是在我們的Causal Mask,玩LLM的各位應該都知道autoregressive model的causal mask大小是一個長寬相同的矩陣,然後藍色區塊的地方設為1,黑色的地方設為0。
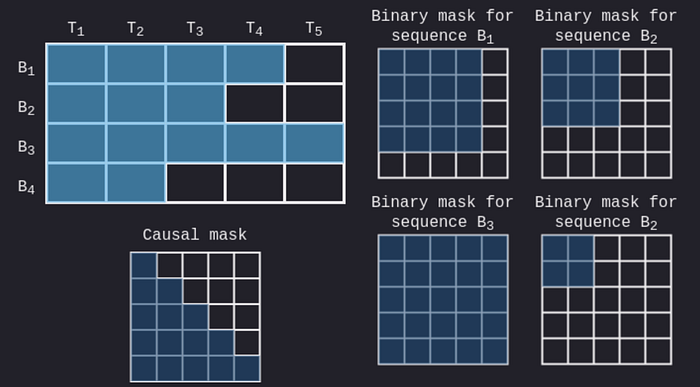
所以今天在做Mask(S)運算的時候,如果這個Block的j>i,也就是causal mask位置是0的地方的話,我們就會自動跳過這個block不做運算。
也就是說將近有快要一半的block都可以跳過,所以這個地方運算就可以加速1.7~1.8倍。
Multi-Thread Block
在FlashAttention V1的運算中,其是使用1個thread block為單位來計算,然後我們會去劃分batch size和attention head,所以這邊總共就會有batch size * attention head個thread block,而
這些thread block會被安排到GPU上的streaming multiprocessor (SM)運行,
像是論文中提到的Nvidia A100 GPU,其有108個streaming multiprocessor (SM)。
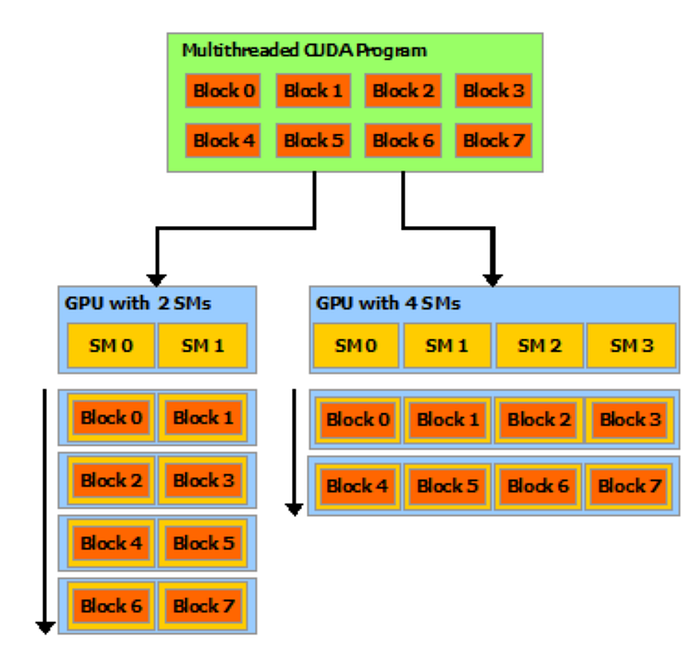
但是我們都知道現在很多模型都主打長sequence length,但是sequence length一長,能開的batch size就會變小,所以就會出現一種情況就是,seuqnece length超長,但是batch size很小、模型的attention head也很小。
如果我們今天同樣用FlashAttention V1的方式來schedule,那這種長sequence length的情況就沒辦法很好的利用SM,所以在FlashAttention V2我們同樣也會以sequence length去劃分。
我們可以進一步看到下面這張圖,白色的地方就是剛剛causal mask提到跳過的block,所以不會做運算。
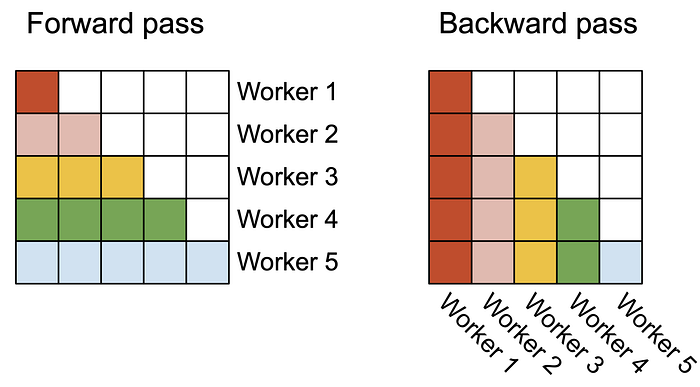
在forward的地方,我們可以看到下面Forward的演算法,output for loop和inner loop的順序被替換掉了,所以是以Row為一個單位丟到worker上運算,至於為什麼Flash Attention V2要刻意替換掉順序,這個等等會提到。
在backward的地方,我們一樣看底下Backward演算法,我們也會以sequence length的維度去切分,不過這邊因為在步驟15中,我們需要把Query state的gradient dQ_i從HBM拉到SRAM,並且還要把更新後的dQ_i寫回去HBM,因為i是屬於column的方向,所以我們我們會以一個column為單位丟掉worker上運算,而這邊outer和inner for loop順序就和原本Flash Attention V1相同
Forward演算法

Backward演算法

Work Partitioning Between Warps
OK上面我們有提到Flash Attention V2在forward的時候outer和inner for loop調換順序了,為什麼呢?在講之前我們會需要了解到
thread block和thread的概念是以logical的角度去看GPU分配算力,但實際上以GPU硬體的角度,真正的運算單位是Warp,而通常一個Warp包含32個thread。
而在Flash Attention的情境當中,一個thread block大概有4或8個warps。
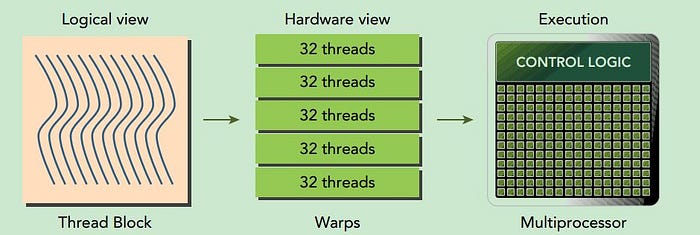
在下面的例子當中,我們假設一個thread block有4個warps,我們可以看到在Flash Attention V1當中,Q和KV的warp做矩陣運算的時候,每一個warp都必須把他們自己算出來的結果先存到thread block的shared memory當中,然後4個warp必須synchronize確保運算完畢,才能再把每個warp的輸出加總起來,而我們可以看到
這中間的bottleneck就是4個warp synchronize,也就是互相等對方的時間。
而今天換成Flash Attention V2的方式,我們把順序調換過來,讓Q的每一個warp對KV做矩陣相乘,如此一來每個warp只要顧好自己那一份的運算就好,不需要synchronize互相等對方,就可以加速Forward運算。
(這部分原先版本描述有錯,感謝下面留言的usafchn fly 糾正)
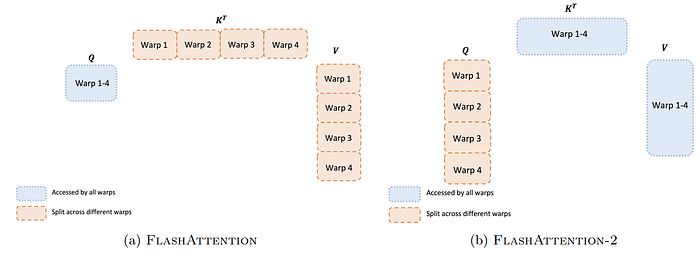
不過在backward的時候,因為上面提到的需要把dQ_i拉到SRAM更新的限制,所以沒辦法用這招來加速。
Tunning Block Size
另外一個可以優化的地方就是我們的Block Size到底要多大,雖然我們在Flash Attention V1推算出B_r和B_c,但顯然這個數字不是最好的。
雖然Block Size越大,Warp越多,可以讓我們減少shared memory I/O的次數越多,但是同樣的也需要更多的register和shared memory,這就可能會造成regiser溢位,也就是記憶體存取速度比存取regiser還慢,造成實際上跑起來速度變慢,另外也有可能shared memory的需求超過GPU本身能提供的大小。
所以在Flash Attention V2也是tune出一個magic number,就是Block size 在{64, 128} × {64, 128}通常會有最好的效果,不過這個還是會需要看我們的head dimension和GPU的shared memory有多大。
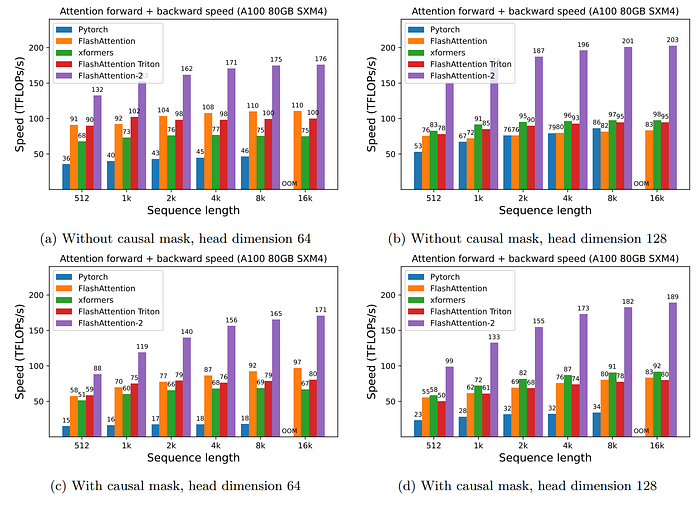
實驗結果
最後我們可以看到Flash Attention V2比V1速度提升了快接近2倍。
FlashAttention V3
OK上面介紹完了Flash Attention V2,接下來我們要來介紹今天的主角Flash Attention V3,這邊先說句大實話,如果你前面Flash Attention V1和V2看的很痛苦的話,那Flash Attention V3你會看的更痛苦。
實際上Flash Attention V2的作者在他們flash_attn官方的github repo有提到
Flash Attention V2在Ampere架構的GPU,像是A100就已經highly optimized了
但是GPU總是推陳出新,A100之後就是赫赫有名的H100,Hopper架構的GPU,而Flash Attention V2在H100上,竟然只能達到GPU 35%的效能利用率。所以作者又提出了更加變態的Flash Attention V3,可以把GPU效能利用率提高到75%,速度比Flash Attention V2提升1.5~2倍。
但是在了解Flash Attention V3的演算法之前,我們得先了解H100相較於A100多了什麼酷東西,讓我們的Flash Attention V3速度可以突破天際。
Hopper Architecture GPU
對於H100的架構相較於A100有什麼特別的,這個要認真講可能又要開一篇,所以我這邊講個大概,但是也不會到隨便帶過。
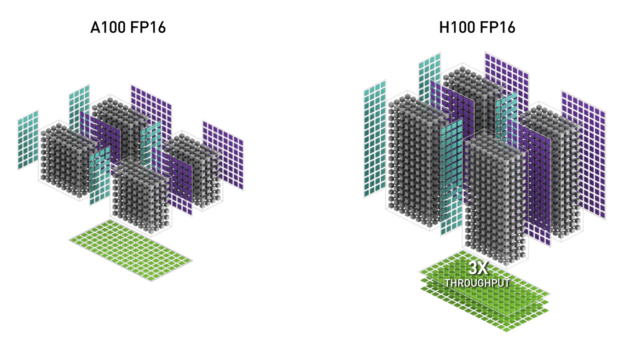
更多更強的SM:
在先前Flash Attention V2我們有提到不同的task會分配到SM上面做運算,所以你可以說SM數量越多,GPU算力越強,而這邊A100有108個SM,H100提升到了132個,而且H100的SM在FP16精度上面的運算速度,在MMA(矩陣相乘累加)的任務上是A100 SM的2倍,所以算一算整體速度H100是A100的3倍左右。
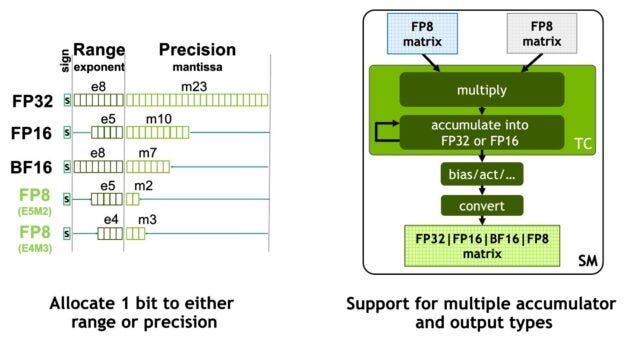
FP8 Tensor Core:
另外H100上面還增加了處理FP8精度的tensor core,可以處理兩種不同format的FP8矩陣運算,而因為FP8的位元表示是FP16的一半,所以H100 FP8的運算是A100 FP16速度的6.4倍
Thread Block Cluster
在前面Flash Attention V2的時候,我們有稍微提到Thread Block的概念,我們可以看到在過往A100 GPU上面,我們會把多個thread分成3個階層,分別是thread、thread block和Grid,而因為H100的SM更多更強,單用3層去分派已經滿足不了更複雜和更龐大的運算任務,所以
H100引入了Thread Block Cluster層,讓thread的調度和記憶體管理上的顆粒度可以再分的更細緻。
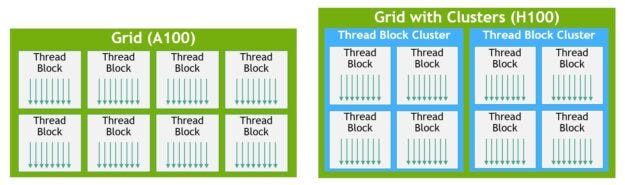
這邊我們講的更細一點,我們可以看到Grid的顆粒度,可以對應到GEME的記憶體區塊,而這就是我們所熟知的HBM,通常這塊記憶體的bandwidth是最慢的,所以我們要做加速運算,會盡量減少從這塊GEME拿資料。

接下來是Thread Block Cluster,硬體上可以對應到Graph Processing Cluster (GPC),而
GPC提供了所謂的SM-to-SM Network,來加速不同SM之間的資料傳輸
我們可以看到在A100當中,如果不同的Thread Block之間要互相傳遞資料的話,需要透過HBM,但是H100中我們可以直接透過SM-to-SM Network來做更有效率的傳輸。而這邊資料physical的位置就是在L2 Cache,Logical的名稱叫做distributed shared memory (DSMEM)。
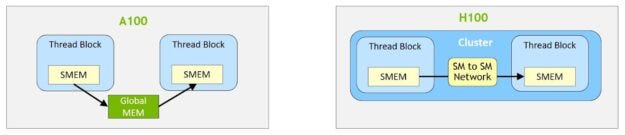
接下來是Thread Block,其也稱之為cooperative thread arrays (CTA),其對應到SM,這邊在前面就有提到過,在Thread Block裡面不同的Thread如果要做資料傳遞的話,就是透過shared memory (SMEM)。
最後就是Thread的啦,對於每一個thread最多可以有256個private register (RMEM)。
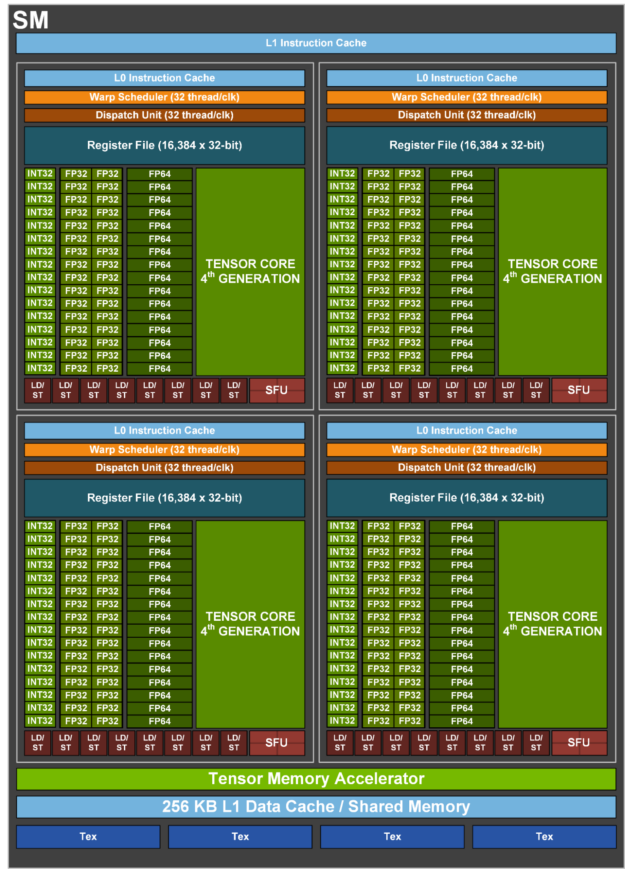
小補充,這邊大家可能會疑問,L1 Cache和L0 Cache在哪?其實我們可以看到H100 SM的架構,L1 Cache在SM當中,而L0 Cache在Warp裡面。
Tensor Memory Accelerator:
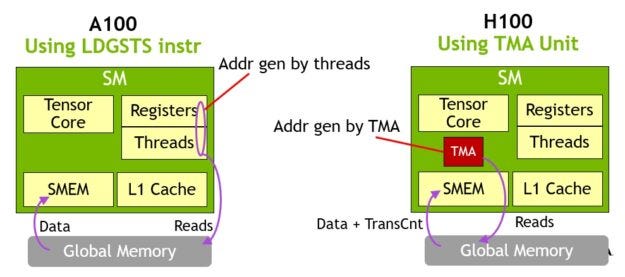
接下來是我覺得H100上最猛的新feature,Tensor Memory Accelerator (TMA),一句話說明這個功能就是:同時在HBM和SMEM傳資料和同時做運算。也就是
computation & communication overlap。
我們可以從下面的例子來看,在之前A100上,如果我們想要把HBM上的資料拉到SM的SMEM上面的話,SM需要先創建一個讀取的thread接下來才會把資料從HBM讀進來,而H100上就是把讀取資料的這件事情交給TMA來處理,如此一來我們就可以釋放更多的算力,讓thread就可以去做它的運算。
Register Dynamic Reallocation:
最後一個也很猛的功能就是動態reallocate register,也就是Warp Group (4個Warps)間的register可以動態做reallocate,讓我們有更多的RMEM可以用。
綜合上面,我們可以看到H100會這麼強不是沒有道理的。
Warp-specialization
OK接下來我們終於要進入倒Flash Attention V3演算法的核心了,在這個地方我們可以把data的傳遞用Producer-Consumer的形式定義
- Producer可以對應到TMA
- Consumer可以對應到Tensor Core
簡單來說就是TMA拿的資料提供給Tensor Core運算。
而這邊所提到的Warp-specialization,指的就是我們可以把Thread Block裡面的warps分成Producer Warp Group和Consumer Warp Group。
- Producer Warp Group做的事情就是用TMA把data從HBM拉到shared memory
- Consumer Warp Group做的事情就是用Tensor Core來計算這些data。
這邊我們進一步看到演算法的地方,在consumer warp group的地方有SS-GEMM和RS-GEMM兩種不同的矩陣運算,這邊SS的意思就是第一個operand是來自shared memory,而RS則是來自register。
為什麼呢?因為要先有Q我們才能做後面的運算,所以說Q一定要先用TMA從HBM拉到shared memory,至於K和V我們可以asynchrony的做,所以我們一開始的時候會初始化一個s-stage circular SMEM buffer去紀錄KV load到shared memory,所以一進入producer這個for loop的時候,
我們不會管consumer到底有沒有把K和V拿去做矩陣運算,直接繼續讀KV直到buffer滿了,也就是經過s次。
而滿了之後我們就會開始等consumer算完attention並釋放這個stage的buffer,之後producer才會再讀取新的K和V。所以算S的時候source是來自shared memory,而算O的時候source是來自register。
另外一個值得一提的就是我們這邊會用Register Dynamic Reallocation去(de)allocations register,增加可以使用的register數量。
畢竟我們可以看到我們這樣分producer和consumer warp group又做asynchronous操作,會需要很多register。

Pingpong scheduling
OK看起來我們的作者,對於讀資料和運算同時做還不夠滿意,所以又加上了一個矩陣運算和Softmax同時運算的效能優化。主要原因是因為
softmax當中的exp運算是由multi-function unit運算,所以說當Tensor Core做矩陣運算的時候,我們同時可以做softmax的運算。
這邊我們可以看到下面的pipeline,我們主要會有三個運算的步驟
- 第一個是QK矩陣運算GEMM0
- 第二的是Softmax算出P
- 最後一個PV矩陣運算GEMM1
而我們今天如果有兩個warp group,我們可以用黑色的虛線也就是synchronization barriers,強制warp group 2 GEMM0做完後,warp group 1才能做GEMM1,而這個就是所謂的Pingpong (乒乓) scheduling
所以原本Flash Attention V2在算Softmax的時候,會浪費掉算力,但是使用了Pingpong scheduling我們可以把矩陣運算塞滿整個時程。
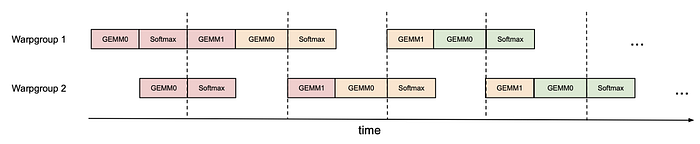
Intra-warpgroup overlapping
OK我們剛剛看到的是針對有2個warp group的情況,那如果今天只有一個warp group呢?沒錯!我們一樣也可以做softmax GEMM overlapping,做法就是我們會把這一個iteration的PV矩陣運算,留到下一個iteration算softmax的時候同時一起做

我們可以從下面的演算法看到,在進入inner for loop之前我們會先計算第一個S_cur=QK(第4行),然後計算softmax(第6行)。接下來進入到inner for loop我們會先在一開始,就去計算下一筆資料的S_next=QK(第9行),而計算的同時我們馬上把這一筆的V load進來,然後發起運算這一筆資料的O=P_curV運算(第11行),到了下一步之後,我們會等待剛剛下一筆的S_next算完,然後接著計算softmax(第13行),這個時候O=P_curV也正在同時運算,最後我們再把S_next複製到S_cur,接著下一個iteration,依此類推。

OK現在我們Flash Attention V3的演算法已經建構好了,接下來我們來看Backward的部分,基本上一樣也是把它拆成producer和consumer warp group一個load資料一個做運算。
我們可以看到因為我們要先recompute S=QK(第21行)和回推dP=dOV(第23行),所以這個地方是SS-GEMM,而dV(第26行)和dK(第27行)的更新,因為Q和dO是透過s-stage buffer管理的,所以是RS-GEMM。
不過這個地方有個麻煩的東西,就是dQ的更新,在Flash Attention V2我們有提到過,他必須拉上來做更新
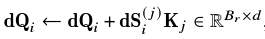
因為這裡不像dV和dK是針對j維度去更新,dQ是針對i維度去更新
會讓不同的thread block同時對同一個地方進行寫入,所以會造成memory contention的問題。
所以這個地方作者開了另一個warp專門來處理dQ,也就是說dSK(第28行)算出來的東西,照理來說我們要加回dQ,但是我們聰明的作者,使用了semaphore(不知道的朋友可以回去複習作業系統)把算出來的結果以atomic的方式加回去HBM上的dQ。

3-stage pipelining
我們在上面的地方看到,Flash Attention V3當中,把整個attention的運算分成兩個stage完成,但我們的作者又想到了一個更瘋狂的3-stage pipeline。
基本上這個想法就是
因為softmax花做多時間運算,所以除了把上一次的PV運算和這一次的Softmax運算同時進行外,當上一次的PV算完後,我們馬上計算下一次的QK
實在是太瘋狂了~
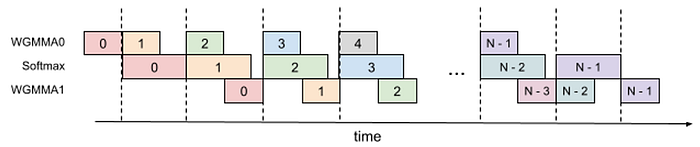
這邊演算法的部分概念和上面的2-stage差不多,所以這邊就留給大家自己study啦!

Low-precision with FP8
contiguous issue
Flash Attention V3另一個突破點,就是支援FP8精度的運算,但是在FP8又會出現新的問題,當我們今天給定一個 𝑀 ×𝐾 矩陣 𝐴 和 𝑁 ×𝐾 矩陣 𝐵 ,做A× 𝐵⊤矩陣運算的時候
- 如果外部 M 或 N 的維度是contiguous的,我們會說 A 或 B operand是mn-major
- 如果內部 K 的維度是contiguous的,則是k-major。
雖然FP16精度在SMEM能接受mn-major和k-major的輸入operand,但是FP8只能接受k-major的輸入operand。
看到這邊大家可能一頭霧水,contiguous是啥?為什麼那麼重要?
這邊可以看PyTorch官方的解說,如果今天有一個tensor x,當我們使用x.contiguous()的時候,如果這個tensor在記憶體當中本身就是連續的,就會返回x本身,但如果不是,則會copy一份x並回傳一份連續的tensor。
而我們今天操作x.transpose(0,1)運算時,其並不會創建一個新的tensor,而是去改變這個tensor的meta data,像是offset和stride,所以經過transpose的x就不是contiguous的。
而tensor不是contiguous,並不是指矩陣裡面element的address隨便分散在記憶體當中,而是指element adress的order被改變過了,所以是不連續的。
OK回到attention的兩個矩陣運算,一個是QK⊤,另一個是PV,而FP8只能支援k-major,所以
必須確保QK⊤運算的時候head dimension是連續的,而PV運算的時候sequence dimension是連續的。
關於這一點一般來說,TMA load進來的QKV基本上head dimension會是連續的,所以QK⊤的運算沒有問題,主要會有問題的是PV運算,我們需要額外加一個Transpose讓sequence dimension符合k-major。
所以在這邊作者用了一個方式,就是
當V load到SMEM後,對V做in-kernel transpose。
實作的方式就是使用LDSM/STSM 指令,這兩個指令分別代表的是把資料從SMEM load到RMEM和把資料從RMEM store到SMEM,而因為這兩個指令都是register efficient的指令,也就是不會用太多register,所以我們可以把in-kernel transpose操作放在producer warp group當中。
WGMMA Layout
另外一個麻煩的點就是,因為我們想要把所有attention的運算用single kernel來算,但是FP32 accumulator會和 FP8 operand layouts產生衝突。這邊我們可以看到底下針對FP32和FP8的WGMMA Layout,他們是長得不一樣的。

所以這邊我們會額外需要一個方法,可以把FP32轉成FP8的layout format:
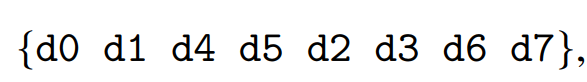
這個意思就是,每8個bytes我們用上面這個format去排序register。
Block Quantization
針對Quantization,因為Flash Attention V3是一個block一個block來運算,所以Quantization也是以Block為單位。
另外我們可以把Quantization這件事情Fused到Attention的前一個步驟,就是Rotary Embedding,而因為Rotary Embedding是memory-bandwidth bound,也就是說I/O時間大於運算時間,所以這邊進行Quantization操作並不會減慢運算速度。
Incoherent processing
最後就是如何避免Quantization Error,這裡我們可以在進入Quantization之前做這樣的操作:(QM) (KM) ⊤ = QK⊤,其中MM⊤ = I,而這裡的M是一個隨機的orthogonal matrix。
而因為QM 或 KM 的每個entry都是 Q 或 K entry的random sum,所以這個方法可以幫助我們來降低Quantization Error
另外為了加速QM和KM的運算,這邊使用了Hadamard transform,也就是把M設為值為±1的random diagonal matrices和Hadamard matrix的product,所以在矩陣相乘的時候時間複雜度就可以從O(d²)降到O(dlogd),同樣的這邊QM和KM的運算一樣可以Fused到rotary embedding當中。
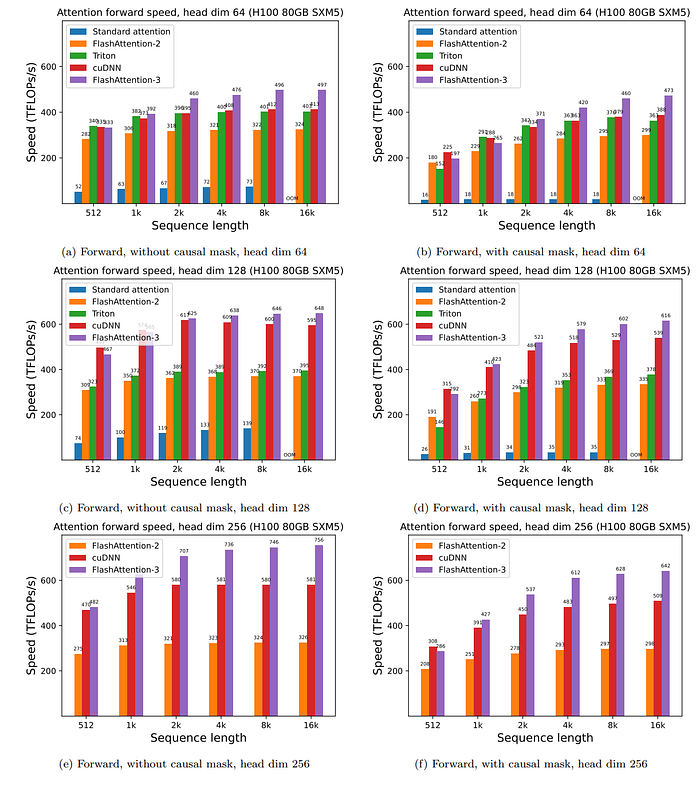
Performance
OK最後我們來看Flash Attention V3的效能,可以看到速度又超越了Flash Attention V2一大截。
Numerical Error
我們可以看到FP8的運算,error壓到了9.1e-3的大小,比baseline低了一個order。

結語
恭喜看到這裡的各位,把Flash Attetention三部曲追完了,不過我真的得說,我真的覺得這三篇paper的難度真的是
Flash Attention V1 << Flash Attention V2 << Flash Attention V3
不過我們見證了,Flash Attention跟隨著GPU的架構去演進,相信B100出來後又會有Flash Attention V4之類的東西出現。
另外我自己覺得H100的這些功能實在是太猛了,其實像是裡面提到的overlap softmax & GEMM的方法,我個人覺得不只可以應用在Attention也可以應用在MLP上面,就是變成overlap SiLU & Element Wise,這邊敲碗哪個大神可以做出來。
還有我真的得說Nvidia實在太強了….,大家可以看到Flash Attention V3的致謝,參與這個project還包含Nvidia CUTLASS和cuDNN團隊。
CUTLASS和cuDNN兩個都是Nvidia的運算加速Library,CUTLASS主要是針對Tensor Core的運算和GPU上的一些硬體特性去優化,而cuDNN是特別針對深度學習常用的一些運算去優化。
所以說如果你今天想要刻一個Flash Attention其實CUTLASS和cuDNN都可以,但是CUTLASS靈活性會更高一點,所以你去看Flash Attention的CUDA code,裡面就是用CUTLASS實作
而這邊關於AMD的部分,其實也是有用HIP刻出來的Flash Attention V2,而這邊CUTLASS可以對應到AMD的Composable Kernel,cuDNN可以對應到AMD的MIOpen,所以AMD的Flash Attention V2就是用Composable Kernel的Library。
至於Flash Attention V3什麼時候可以跑在AMD MI300上呢?這個作者在GitHub上說,有在規劃了(感動~),所以應該可以期待一下。
最後祝大家工作順利啦!
作者:劉智皓
LinkedIn:Chih-Hao Liu
Reference
[1] Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35, 16344–16359.
[2] Dao, T. (2023). Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
[3] Shah, J., Bikshandi, G., Zhang, Y., Thakkar, V., Ramani, P., & Dao, T. (2024). Flashattention-3: Fast and accurate attention with asynchrony and low-precision. arXiv preprint arXiv:2407.08608.
[4] CUDA C++ Programming Guide, Release 12.6, NVIDIA Corporation
[5] 深入解析 NVIDIA Hopper 架構, https://blogs.nvidia.com.tw/blog/nvidia-hopper-architecture-in-depth/
